首先声明本帖首发于赏金论坛,希望大家能多多关注这个正在成长的论坛www.sgoldcn.com
想要编写自己的反汇编引擎并不是一件难事,只不过是要学习大量指令相关东西。学习指令最详细的文档莫过于官方手册,但由于是英文的,让很多新手无法着手。这里我提供一些中文与英文的教程,大家可以全面参考。因为已经有人讲解了指令格式等基本的东西,所以这里我就不再讲解了,需要时只做编程需要的描述。先说明一下,我的代码是查表法,自己建立Opcode表来进行查询,随后放出来的只是解码引擎,不加翻译成助记符的模块。因为翻译模块当时选用了让我现在无比懊悔的switch case,导致有很多已知和未知的翻译错误,解码引擎可以说是基本不会有错误,可以正确解码4张opcode表、Group表、FPU表,因为当时写引擎时定位的就是能够解码全部intel指令,现在基本已经达到了。 写的时候得到了同事的帮助,在此表示感谢。
中文教程:
打造自己的反汇编引擎Intel指令编码学习报告
intel指令格式与长度反汇编引擎ADE32分析 http://bbs.pediy.com/showthread.php?t=54180
x86/x64 指令编码内幕(适用于 AMD/Intel)http://www.mouseos.com/x64/index.html
x64 指令系统之指令编码内幕http://linux.chinaunix.net/bbs/viewthread.php?tid=1050480
关于MMX指令 http://dev.gameres.com/search_articles.asp?page=1&name=MMX
Inetl官方手册汉化版,看雪上有翻译好的。
英文教程:
《ArtOfDisassembly》 如果英文好,一定要看这个教程
关于x86指令比较好的英文站点http://www.sandpile.org/
Inetl官方手册下载 http://www.intel.com/products/processor/manuals/
AMD官方手册下载 http://developer.amd.com/documentation/guides/Pages/default.aspx
代码:
一个超轻量级的反汇编引擎 http://cyclotron.ycool.com/post.2758008.html
XDE反汇编引擎源代码 http://www.zeroplace.cn/article.asp?id=142
OllyDBG代码
上面这些信息足够足够用了,如果英文好的话,《ArtOfDisassembly》一定要看,非常不错的教程。由于这里我不偏重于基础,而是拿代码说话,所以我假设你已经对指令格式等有所了解,如果你不了解就看我写的这些东西,你会觉得我说的不清不楚,不明不白,你看的也会是云里雾里。如果看官方手册,必须看的是《Volume 2A:Instruction Set Reference, A-M》中的CHAPTER 2 INSTRUCTION FORMAT,即第2章。《Volume 2B: Instruction Set Reference, N-Z》中的Appendix A Opcode Map,即附录A。
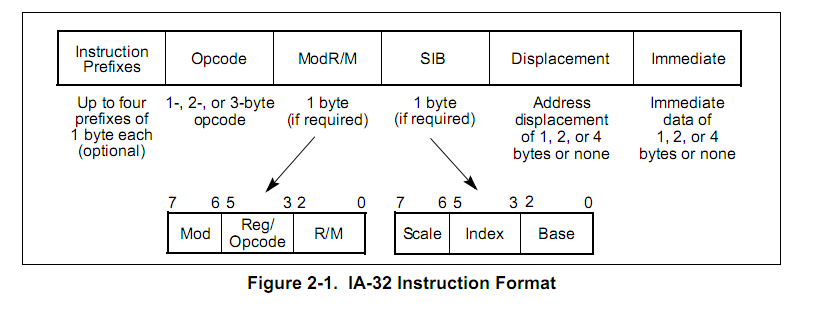
上面这张图是指令格式,可以看到由6部分组成,所以我们应该定义一个结构体,并且结构体中应该包含以上六个部分,这样才能在翻译指令时把指令的各部分信息保存在结构体中。
typedef struct _INSTRUCTION
{
BYTE RepeatPrefix; //重复指令前缀
BYTE SegmentPrefix; //段前缀
BYTE OperandPrefix; //操作数大小前缀0x66
BYTE AddressPrefix; //地址大小前缀0x67
BYTE Opcode1; //opcode1
BYTE Opcode2; //opcode2
BYTE Opcode3; //opcode3
BYTE Modrm; //modrm
BYTE SIB; //sib
union //displacement联合体
{
BYTE DispByte;
WORD DispWord;
DWORD DispDword;
}Displacement;
union //immediate联合体
{
BYTE ImmByte;
WORD ImmWord;
DWORD ImmDword;
}Immediate;
BYTE; InstructionBuf[32]; //保存指令代码
DWORD dwInstructionLen; //返回指令长度
}INSTRUCTION,*PINSTRUCTION;
指令前缀Instruction prefixes由4部分组成,所以这里我也直接定义了4个部分。
指令前缀共有以下4组,一条指令最多可使用4种不同组前缀。
重复与锁指令: F0 Lock
F2 REPNE/REPNZ (cmps,scas)
F3 REP (movs,ins outs,lods,stos)
REPE/REPZ (cmps,scas)
段改写与分支指令: 2E CS
36 SS
3E DS
26 ES
64 FS
65 GS
2E 分支未实现
3E 分支实现
操作数大小改写指令:66 改变操作数大小
地址大小改写指令: 67 改变寻址方式
Opcode是可变的,有三种可能:1字节、2字节、3字节,所以定义了三个Opcode。Modrm与SIB没什么可说的,直接定义就行了。Displacement 与Immediate都被定义成了联合体,因为他们也都是可变的,有可能是1字节、1字、1双字大小。最后一个dwInstructionLen是保存指令的长度,一条指令最短只要1字节,最长…自己数数吧。
定义好指令格式结构体之后,我们还需要把4张Opcode表(没错,是4张,因为第三张表还会被分成2张表)和1张Group表还有FPU表用自己的方式表示出来。为了能描述所有的表,我们还需要定义自己的标志。
#define ModRM 0x00000001 //含有ModRM
#define Imm8 0x00000002 //后面跟着1字节立即数
#define Imm16 0x00000004 //后面跟着2字节立即数
#define Imm66 0x00000008 //后面跟着立即数(Immediate),立即数长度得看是否有0x66前缀
#define Addr67 0x00000010 //后面跟着偏移量(Displacement),偏移量长度得看是否有0x67前缀
#define OneByte 0x00000020 //只有1个字节,这1个字节独立成一个指令
#define Mxx 0x00100000 //mod != 11时才可解码
#define TwoOpCode0F 0x00000040 //0x0F,2个opcode
#define Group 0x00000200 //Group表opcode
#define Reserved 0x00000400 //保留
#define PreSegment 0x00400000 //段前缀
#define PreOperandSize66 0x00800000 //指令大小前缀0x66
#define PreAddressSize67 0x01000000 //地址大小前缀0x67
#define PreLockF0 0x02000000 //锁前缀0xF0
#define PreRep 0x04000000 //重复前缀
#define Prefix (PreSegment+PreOperandSize66+PreAddressSize67+PreLockF0+PreRep)
看到上面这些东西,大家一定有打退堂鼓的意思了。其实没那么难,只要你像我说的,在看这些之前先学习上面的教程,这些东西你肯定能看得懂的,而且每行后面我也做了注释。上面这些只是列出了opcode表1能用到的标志,像opcode表2和3还有Group与FPU都没列出来。其实写这个引擎最难的也就是定义标志,然后把几张表里面填充相应标志。
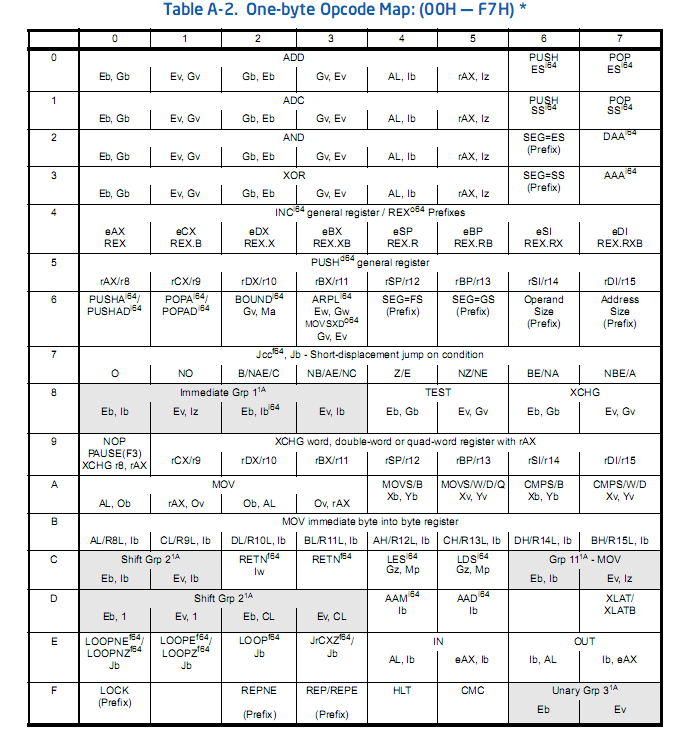
来看看这张表,这是opcode1的表,表里面的每个部分都很重要,甚至一个字母的差别都会影响指令的走向。像Eb、Gb、Ev、Gv等都代表着这个指令的一些特性,不要偷懒,好好把上面的教程看了,你会懂的,最好看官方原版手册。
好了,现在开始填表,先来填Opcode1表:
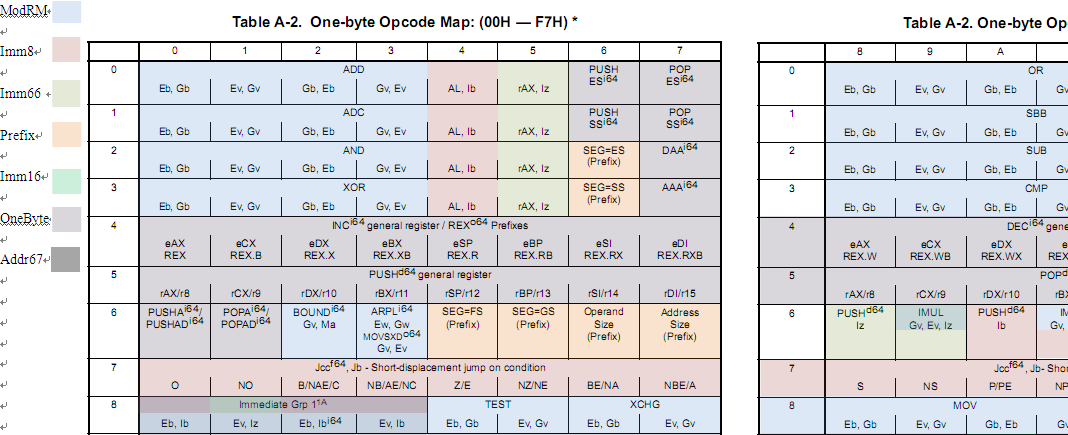
Opcode1表我在word里面填充了一下,每个不同的颜色都需要不同的处理,在word里我只填充了Opcode1,其他表格我都是拿着不同颜色的笔在纸上画出来的,想学习就别偷懒,自己赶紧画一下吧。填充表格不是一天两天、一个星期两个星期能完成的,可能需要你一个月两个月。所以,想写引擎确实是个苦力活,不是编写的难点太多,而是难在太多简单却冗长的工作要做。
至于如何填表,我这里举上几例,如表格的第一项00,他是ADD指令,下标是Eb,Gb
E: A ModR/M byte follows the opcode and specifies the operand. Opcode后面跟着ModRM
G: The reg field of the ModR/M byte selects a general register. ModRM中的reg被用作选择通用寄存器
b: Byte, regardless of operand-size attribute.不管是否有66前缀操作数都只是一个字节
可见,E和G都说明这个指令需要ModRM,所以填充标志为ModRM。再来看一个8D,大家可以看官方手册《Volume 2B: Instruction Set Reference, N-Z》的Appendix A Opcode Map,即附录A,里面有所有的表。8D这条指令是LEA,下标是Gv,M,G我们已经知道了,说明这条指令肯定有ModRM,再来看M和v:
M:The ModR/M byte may refer only to memory (for example, BOUND, LES, LDS, LSS, LFS, LGS, CMPXCHG8B). ModRM只能用于内存操作数。
可见这个M里面还是有说道的,所以我们必须去查一下关于ModRM的说明。来到《Volume 2A:Instruction Set Reference, A-M》中的CHAPTER 2 INSTRUCTION FORMAT,即第2章看一下。

从这张图里可以看到,当ModRM中的Mod不等于11时才有寻址内存的操作,像[EAX]、[EBX]+disp32等。所以这个M标志要说明的就是ModRM中的Mod != 11,所以我们定义了一个标志Mxx,只能在Mod != 11时才可解码,如果等于了11,说明没这条指令。
#define Mxx 0x00100000 //mod != 11时才可解码
所以8D指令的标志应该是ModRM+Mxx。
用OD1.0测试一下8D指令:
0040322B 8D00 LEA EAX,DWORD PTR DS:[EAX]
0040322D 8DC0 LEA EAX,EAX ; 非法使用寄存器
可以看到8D00可以正常显示,因为Mod == 00,而8DC0是不应该显示的,因为Mod ==11,但这里OD给解码了,这是OD的Bug,用WinDBG就不会解码8DC0:
7c9211e0 8d ???
7c9211e1 c00000 rol byte ptr [eax],0
因为8DC0不能组成一组有效的指令,所以直接显示成???,并把C0当成下一组指令的代码, OD2.0版本也未修正这个Bug,初学者不建议用OD,因为他有许多Bug会误导你,可以使用WinDBG,毕竟微软的东西还是信得过的,虽然他的引擎中我也发现过解码错误,但是非常的少。OD的引擎不是很完美,解码会出现很多错误,我已经向Olly本人发过多个BugReport,他也回复说会在下个版本中修正。
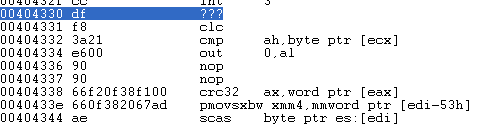
WinDBG的引擎解码错误的指令我没有记录,只记得个crc32指令,错误在官方手册里面说CRC32 r32, r/m8,目的操作数只能是32位寄存器,而WinDBG用的是ax,大家可以查一下OD2.0与IDA,使用的都是EAX。
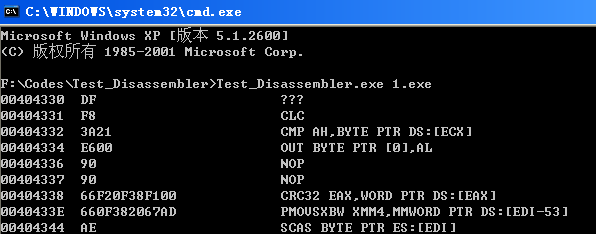
WinDBG:
其实,我有很多细节都省略掉了,真正打算学习反汇编引擎的人是会深挖进去的,如果想写一个自己的引擎,那就先动手去填写标志吧。最后填充完是这样子的:
/************************************************************************/
/* 1个opcode指令表 */
/************************************************************************/
DWORD OneOpCodeMapTable[256]=
{
/* 0 1 2 … E F */
/*0*/ ModRM, ModRM, …, OneByte, TwoOpCode0F,
/*1*/ ModRM, ModRM, …, OneByte, OneByte,
/*2*/ ModRM, ModRM, …, PreSegment, OneByte,
……
/*F*/ PreLockF0, OneByte, … Group, Group
};
一个表最多是256条指令,所以定义的大小为256。
今天先到这吧。
opcode1表填充图.rar (178 K)
Test_Disassembler.rar (4505 K)
您正在看的文章来自赏金论坛 http://www.sgoldcn.com,原文地址:http://www.sgoldcn.com/read.php?tid=915.如有转载,请误删除此信息
- 标 题:编写自己的反汇编引擎
- 作 者:AlexLong
- 时 间:2011-01-20 19:30:09
- 链 接:http://bbs.pediy.com/showthread.php?t=128411