 最近仙果兄弟有一篇exploit分析的文章,里面提及了“纯字母shellcode”这个概念,回头翻翻以前调试过的一个exploit,里面就是用的这种shellcode编码技术,现在把它提出来跟大家交流交流。
最近仙果兄弟有一篇exploit分析的文章,里面提及了“纯字母shellcode”这个概念,回头翻翻以前调试过的一个exploit,里面就是用的这种shellcode编码技术,现在把它提出来跟大家交流交流。
现在很多exploit的中使用的shellcode看起来貌似离我们常见的常规汇编的机器码大相径庭,好像只是一段来来回回的有效字符串(如字母,数字等等),而且单单对这段字符串进行反汇编看到的东西往往让我们匪夷所思,这里我们就来看看这样的shellcode是怎么回事。
首先举个例子:
前几天抓到的一个exploit样本里面,shellcode的主体是这样的一段:

这个看起来只是一段来来回回略有规律的字符串,但是从整个exploit来看这里确实是一段shellcode而且代码中是以shellcode为变量名来命名的,我们对它进行静态反汇编看看有没有什么发现:
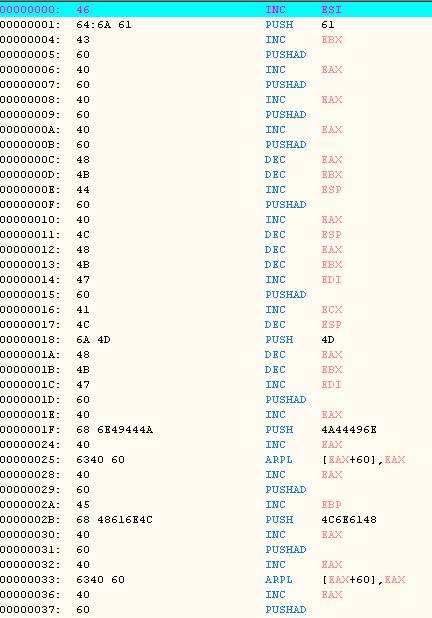
我们应该会觉得这个如果是shellcode的话,那也太神奇了吧!
难道是反汇编器欺骗了我们?
呵呵,其实应该是我们没有深入的理解吧,或许是忽略了exploit里面一些重要的东西?唯一的解释就是----我们看到的shellcode是被进行了特殊处理的shellcode。
这个如果是shellcode主体的话,那只能说明在exploit中还是有另外一小段代码是对这段shellcode进行解码的。
再对exploit进行动态分析,我们察觉溢出之后跳到的一段代码并不是我们现在看到的纯字母shellcode,而是下面这一段:

呵呵,多了前面的33个字符:
![]()
真相就在这里:

看来确实是对下面的一段“纯字母shellcode”进行解码的。
对应的编码代码,我们将它翻译成C代码如下:
代码:
for (int i = 0;i < codeLen; i++)
{
low_al = ((byte *)decodescEnd)[i] & 0x0f;
hi_ah = (((byte *)decodescEnd)[i] & 0xf0) >> 4;
if (low_al > 0x8)
{
newscBuff[decodeLen+2*i + 1] = 0x40 + low_al;
}
else
{
newscBuff[decodeLen+2*i + 1] = 0x60 + low_al;
}
if (hi_ah > 0x8)
{
newscBuff[decodeLen+2*i] = 0x60 + hi_ah;
}
else
{
newscBuff[decodeLen+2*i] = 0x40 + hi_ah;
}
}

反汇编如下:

这下似曾相识了吧!对了,这就是shellcode的本来面貌。
下面我们来总结下:
其实所谓的纯字母shellcode只不过是对真正shellcode 的一种巧妙的编码方式而已,从思路上讲,效果无异于异或之类的编码方式。作为一个exploit学习者来讲,真相往往就是置身在exploit其中,我们能不能看穿实际上就是看学习者本身的研究深入程度了。
本篇文章没有多大技术含量只是说明一些小问题,各位达人见笑了~~
