前几天学习了switch结构,让我有了新的认识,于是有了这篇文章,由于是用零碎时间写的,完成后没有检查(偷懒了^_^),如有错误欢迎大家指出。另外本人文采不好,语言组织和表达能力也很差,只希望能引导一下和我一样菜的朋友。
首先我们来对照源代码来反汇编一下几种switch的情况。
第一种
源码部分:
int n = 0;
switch (n)
{
case 0:
printf("0\r\n");
break;
case 1:
printf("0\r\n");
break;
case 2:
printf("0\r\n");
break;
default:
printf("0\r\n");
}
然后我们来看一下这种情况的反汇编代码

通过反汇编代码可以很清晰的看出,这里是直接将switch优化 if,这也是大家普遍的想法。
如果你以前是这样以为switch其实就是一个if,那么请继续向下看。
第二种
源码部分:
int n = 0;
switch (n)
{
case 0:
printf("0\r\n");
break;
case 1:
printf("0\r\n");
break;
case 2:
printf("0\r\n");
break;
case 3:
printf("0\r\n");
break;
default:
printf("0\r\n");
}
这里与上面相比,无非是多了一个case分支而已,反汇编情况大家跟我继续看

大家可以看到,我多加了一个分支,情况就改变了,并不是我们开始认为是if的那种情况了。
接下来我们慢慢分析这几句代码的含义。首先我们看到有一个n与3的比较指令,那么这里是什么含义呢?看一下源代码发现我们有三个case块,那么想一下这个3是不是就是比较case块的个数呢,这里就改一下源代码再来看一看有什么变化。
int n = 0;
switch (n)
{
case 0:
printf("0\r\n");
break;
case 1:
printf("0\r\n");
break;
case 2:
printf("0\r\n");
break;
case 4:
printf("0\r\n");
break;
default:
printf("0\r\n");
}
这里我只是做了轻微的改动,把case 3 改为 case 4,仅此而已,我们再来看一下反汇编代码

大家注意看00401035这一行,这里变成了n与4进行比较,这说明什么呢?我只是修改了一下 case X 的数值,所以可以猜想,switch 的这种情况首先对我们case X 的值进行了排序,而且是从小到大的排序,那么下面的那一句ja就很好理解了,如果大于4,则说明不存在这个分支,就jmp到default。接下来问题又来了,那么 ecx*4+4010A1 又是什么呢?稍微懂点逆向的应该想到这里和数组结构很相似,没错,这里就是一个地址表数组。
我们在dump中跟随一下
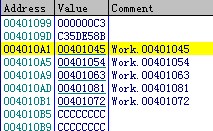
我们可以看到这里有5个地址(我们暂且叫这地址表数组),其实如果跟随过去就可以看到,这几个地址分别对应了switch的几个分支,当然不包括default。我截一个详细的反汇编代码图让大家对照一下这里的地址。
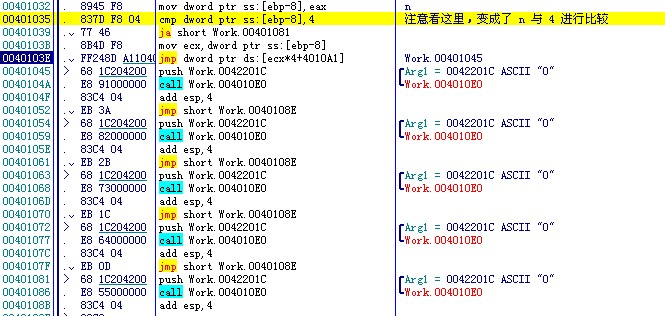
大家对照一下地址看看我们上面得出的结论没错吧。这时候有人要问了,既然不包括default分支,那怎么会有5个地址呢,而且第四个地址是default,第五个地址是case 4的处理代码,这样理下来的话也对应不起来呀?其实这里就是我要说的地方了,其实switch在这里其实是把case 的不连续的值或者说是case 空缺的值给补上了,而且默认补上的处理地址是default,也就是说case 2 到 case 4 ,中间缺了case 3, switch在优化的时候,编译器自动将case 3插了进去,而且也给这个case 3一个块处理地址,即为default的块处理地址。
到这里我们就把switch的这种处理方式搞清楚了,下面我就再来口头描述一下switch的这种处理方式。
1、 将case 的值 从小到大排序
2、 如果case 的值中间有空缺,那么编译器会自动补上,而且它的块处理地址为default。
3、 构造一个case块地址表,存放处理代码的地址
4、 然后通过n的值来查找相应的case处理地址(这里大家可以代几个数来看一下0040103E这行代码,之所以能这样做的原因,是因为前面进行了排序操作,构成了一个从小到大排列的数组)
第三种
源码部分:
int n = 0;
switch (n)
{
case 0:
printf("0\r\n");
break;
case 1:
printf("0\r\n");
break;
case 2:
printf("0\r\n");
break;
case 150:
printf("0\r\n");
break;
default:
printf("0\r\n");
}
大家可以看到,这里我又只是做了一点轻微的操作,把case的值变大了,那么我来帖一下反汇编代码。
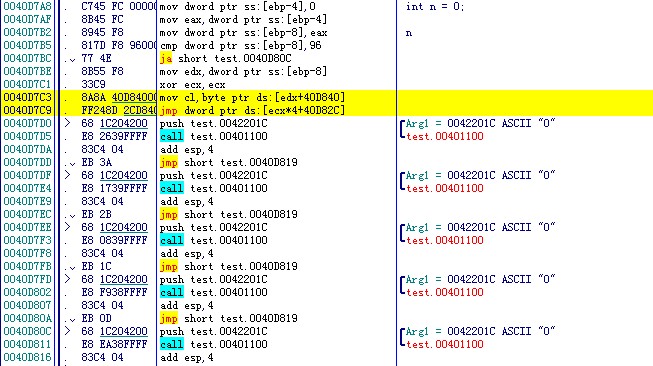
大家注意一下我选中的两行指令,我们发现这里比第二种情况最大的区别就是多了一条指令,0040D7C3这一句指令是在第二种情况中不存在的,那么edx+40D840又是什么东西呢,同样去dump窗口观察一下。
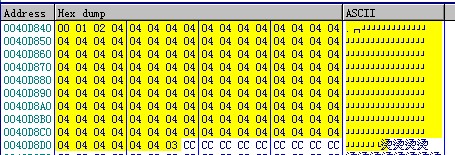
我们可以看到这里有很多重复的数值4,也有几个其他的数值,那里这里到底是什么呢?其实这里是一张表,我们姑且称它为索引表,也是一个数组,每个元素都是一个char类型,我们数一下我选中的这些char,发现一共有151个。大家可以看到源码中我写的值是case 150,那么从case 0 到 case 150 如果中间数据齐全的话,总共有151个case。没错,这里是索引表就是case的值的集合,当然中间空缺的值他也都给补上了,这里他补的是04,对照源码从0开始数,4正好是我们的default。也就是说中间空缺数值都被填写成default了(但是地址表里面却只有一个default地址,上面说的第二种情况在地址表中有很多重复的default地址),然后和第二种方法类似,通过这里的索引表来到达相应的块处理代码处。
这里索引表的目的就是为了定位到相应case块处理代码处,每一个元素只占一个char,也没有很多重复的4个字节的default地址,有的只不过是default的索引值罢了,也就是相对于第二条做的优化,如果用第二种方法来处理这种数值相差很大的数,占用的字节就很多了。
我们再来简单的过一下:
1、 排序
2、 构造索引表(char数组)和地址表(4字节的地址数组),将case空缺的值补在索引表中,并且默认索引号为default的索引号,索引表中会有多个default的索引,但是地址表中只有一个default的块处理地址(这里也就是相对于第二条的优化)
3、 通过n的值找到对应的索引号,然后再寻找对应的块处理地址
第四种
源代码部分:
int n = 0;
switch (n)
{
case 0:
printf("0\r\n");
break;
case 1:
printf("0\r\n");
break;
case 2:
printf("0\r\n");
break;
case 3:
printf("0\r\n");
break;
case 255:
printf("0\r\n");
break;
default:
printf("0\r\n");
}
还是很轻微的修改,大家可以看到,我几次修改代码,大部分都是case 的差值改变了,继续看反汇编代码。
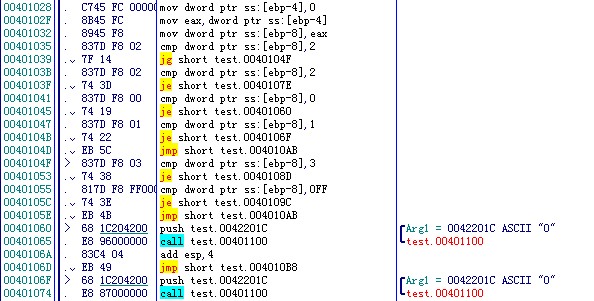
到这里又是不同的情况了,前面第一种情况是直接转换成if,第二种情况是地址表,第三种情况是索引表和地址表,看到这里第四种情况的反汇编代码,大家是不是猜想现在是和第一种情况一样,转换成了if呢?其实不然,大家仔细观察几句cmp指令,第一次比较为
cmp dword ptr ss:[ebp-8],2 , 这里是与2进行比较,2又是什么呢?我们首先将代码中可以看到的case的值进行排序,不考虑前几总情况自己补齐的情况,排序后如下:0 1 2 3 255。
此时2正好是中间数,顺着反汇编代码继续看,如果小于2则继续往下走,变成了第一种的if了。这里的第四种情况就是用折半的方法查找对应的值,慢慢缩小范围,直到剩余数量小于等于3的时候(也就是满足第一种情况条件的时候),转为if。
最后来简单总结一下switch的4种方式
1、 case个数小于等于3,用第一种方式
2、 case个数大于三
3、 case差值小于255
4、 case差值大于等于255
其中2与3的界线取决于具体的环境,以上代码在VC6+SP3下测试。
不同的环境和编译器可能结果会有所不同,而且编译器的优化也会有不同。
刚刚学习,高人飘过,如果错误谢谢指正~
- 标 题:switch 学习报告
- 作 者:dwboy
- 时 间:2010-04-30 19:30:56
- 链 接:http://bbs.pediy.com/showthread.php?t=112107
 ,可能同时存在上述几个方式
,可能同时存在上述几个方式