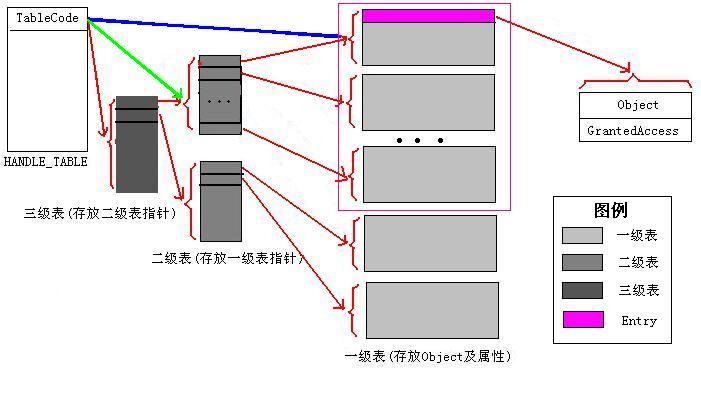
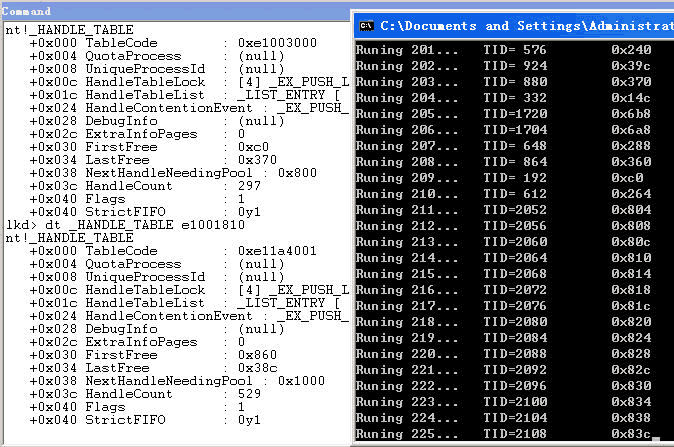
前置知识:Windows句柄表的基本结构
本文以WRK1.2的代码为参考,主要分析Windows句柄表的分配算法,其实只要了解了句柄表的结构,就很容易理解在分配句柄表过程中的每一步操作是何含义,理解之后你会感觉,这个其实算不上什么算法,只能叫做一个规则吧
一、首先来看ExCreateHandleTable(),该函数创建一个HANDLE_TABLE结构;
其过程是调用ExpAllocateHandleTable()完成申请HANDLE_TABLE的工作,然后把申请到的HANDLE_TABLE放到句柄表双链中去
所有进程的HANDLE_TABLE就这样连接在一起(如果有人用过ZwQuerySystemInformation枚举系统中的所有句柄时,就是沿着这条双向链表走的),而PspCidTable也由该函数创建,但这后又被从该双链中移除,成为一个独立的句柄表(谁让它特殊~)
代码:
//核心是下面两句 HandleTable = ExpAllocateHandleTable( Process, TRUE );//创建句柄表 InsertTailList( &HandleTableListHead, &HandleTable->HandleTableList );//放入双向链表中
PHANDLE_TABLE
ExpAllocateHandleTable (
IN PEPROCESS Process OPTIONAL,
IN BOOLEAN DoInit
);
过程分析:
1.申请一块PagedPool作为HANDLE_TABLE,大小为sizeof(HANDLE_TABLE)
2.为HANDLE_TABLE申请一块PagePool内存作为第一个一级表,大小为PAGE_SIZE,以后的一级表由ExpAllocateLowLevelTable来申请
//设置TableCode为刚申请的一级表,这里其实隐含了句柄表为一级这个事实
代码:
//前面省略小部分申请内存的代码
HandleTable->TableCode = (ULONG_PTR)HandleTableTable;
//下面是对这个刚申请的一级表进行初始化
HandleEntry = &HandleTableTable[0]; //第一个HANDLE_TABLE_ENTRY
HandleEntry->NextFreeTableEntry = EX_ADDITIONAL_INFO_SIGNATURE;//-2,作为标志;
HandleEntry->Value = 0; //对象值为0,对应于无效句柄NULL
//
// For duplicate calls we skip building the free list as we rebuild it manually as
// we traverse the old table we are duplicating
//
if (DoInit) { //这个参数在普通调用时为TRUE,仅在复制句柄表时则为False,因为复制时并不需要重新分配句柄
HandleEntry++; //从第二个HANDLE_TABLE_ENTRY开始
//
// Now setup the free list. We do this by chaining together the free
// entries such that each free entry give the next free index (i.e.,
// like a fat chain). The chain is terminated with a 0. Note that
// we'll skip handle zero because our callers will get that value
// confused with null.
//
for (i = 1; i < LOWLEVEL_COUNT - 1; i += 1) {
HandleEntry->Value = 0; //对象值初始化为0
//FreeHandle即自由的,未被使用的句柄
HandleEntry->NextFreeTableEntry = (i+1)*HANDLE_VALUE_INC; //构建FreeHandle列表,在初始化时,每一个HANDLE_TABLE_ENTRY都指向下一个句柄.这里的NextFreeTableEntry的值准确说是下一个FreeHandle,这样构成了一个单向链表一样的结构
HandleEntry++;
}
//对最后一项作特殊处理
HandleEntry->Value = 0;
HandleEntry->NextFreeTableEntry = 0; //最后一项的NextFreeTableEntry为0
HandleTable->FirstFree = HANDLE_VALUE_INC; //把刚初始化完的句柄表的FirstFree设为4,即第一个可用句柄
}
HandleTable->NextHandleNeedingPool = LOWLEVEL_COUNT * HANDLE_VALUE_INC; //一级表最大句柄
//
// Setup the necessary process information
//
HandleTable->QuotaProcess = Process; //设置所属的Process
HandleTable->UniqueProcessId = PsGetCurrentProcess()->UniqueProcessId; //调置所属Process的ProcessId
HandleTable->Flags = 0;
二、申请低级表,即最底层一级的表.每个HANDLE_TABLE的第一个一级表在创建HANDLE_TABLE时就被创建了,ExpAllocateLowLevelTable用于提供在其它时候创建一级表的支持,比如句柄表已经为二级时再申请句柄表时只需要申请创建一个一级表并加入二级表中即可.
代码:
PHANDLE_TABLE_ENTRY
ExpAllocateLowLevelTable (
IN PHANDLE_TABLE HandleTable,
IN BOOLEAN DoInit
)
/*++
Routine Description:
This worker routine allocates a new low level table
Note: The caller must have already locked the handle table
Arguments:
HandleTable - Supplies the handle table being used
DoInit - If FALSE the caller (duplicate) doesn't need the free list maintained
Return Value:
Returns - a pointer to a low-level table if allocation is
successful otherwise the return value is null.
--*/
{
ULONG k;
PHANDLE_TABLE_ENTRY NewLowLevel = NULL, HandleEntry;
ULONG BaseHandle;
//
// Allocate the pool for lower level
//
NewLowLevel = ExpAllocateTablePagedPoolNoZero( HandleTable->QuotaProcess,
TABLE_PAGE_SIZE
);//申请内存,大小为一级表的大小TABLE_PAGE_SIZE
if (NewLowLevel == NULL) {
return NULL;
}
//
// We stamp with EX_ADDITIONAL_INFO_SIGNATURE to recognize in the future this
// is a special information entry
//
//下面三行代码为初始化,这个同刚创建HANDLE_TABLE时创建第一个一级表时的工作基本相同,不多说
HandleEntry = &NewLowLevel[0];
HandleEntry->NextFreeTableEntry = EX_ADDITIONAL_INFO_SIGNATURE;
HandleEntry->Value = 0;
//
// Initialize the free list within this page if the caller wants this
//
if (DoInit) {
HandleEntry++;
//
// Now add the new entries to the free list. To do this we
// chain the new free entries together. We are guaranteed to
// have at least one new buffer. The second buffer we need
// to check for.
//
// We reserve the first entry in the table to the structure with
// additional info
//
//
// Do the guaranteed first buffer
//
//这里是构建FreeHandleList,也是将每一个HANDLE_TABLE_ENTRY的NextFreeTableEntry指向下一个可用句柄.
//但是由于这里不是第一个一级表,所以句柄值的计算稍有不同,需要考虑加上前面的部分
BaseHandle = HandleTable->NextHandleNeedingPool + 2 * HANDLE_VALUE_INC;
//BaseHandle是当前新分配的句柄表中的最小句柄+4,即未申请本表时的最大Handle(句柄表的最大Handle即HandleTable->NextHandleNeedingPool)再加上8,也就是说跳过了第一个用作无效标记的HANDLE_TABLE_ENTRY(占一个句柄索引),以第二个作为新句柄表起始点的HANDLE_TABLE_ENTRY为起始点(因为第二个HANDLE_TABLE_ENTRY才是有效的,因此从这里开始构建FreeHandleList的话,它的下一个FreeHandle应该指向第三个HANDLE_TABLE_ENTRY,而第三个HANDLE_TABLE_ENTRY的句柄在当前句柄表内的偏移为2*HANDLE_VALUE_INC=8)
for (k = BaseHandle; k < BaseHandle + (LOWLEVEL_COUNT - 2) * HANDLE_VALUE_INC; k += HANDLE_VALUE_INC) {
//k的值为BaseHandle开始,以HANDLE_VALUE_INC递增,增量为4
HandleEntry->NextFreeTableEntry = k; //这里构建了FreeHandleList,可以实验观察之
HandleEntry->Value = 0;
HandleEntry++;
}
HandleEntry->NextFreeTableEntry = 0; //最后一个置0,作为结束标记
HandleEntry->Value = 0;
}
return NewLowLevel;
}
三、当需要申请一个新的二级表(MidLevelTable)时,调用此函数
代码:
PHANDLE_TABLE_ENTRY *
ExpAllocateMidLevelTable (
IN PHANDLE_TABLE HandleTable,
IN BOOLEAN DoInit,
OUT PHANDLE_TABLE_ENTRY *pNewLowLevel
)
/*++
Routine Description:
This worker routine allocates a mid-level table. This is an array with
pointers to low-level tables.
It will allocate also a low-level table and will save it in the first index
Note: The caller must have already locked the handle table
Arguments:
HandleTable - Supplies the handle table being used
DoInit - If FALSE the caller (duplicate) does not want the free list build
pNewLowLevel - Returns the new low level table for later free list chaining
Return Value:
Returns a pointer to the new mid-level table allocated
--*/
{
PHANDLE_TABLE_ENTRY *NewMidLevel;
PHANDLE_TABLE_ENTRY NewLowLevel;
NewMidLevel = ExpAllocateTablePagedPool( HandleTable->QuotaProcess,
PAGE_SIZE
); //申请一块内存作为MidLevel,即二级表,大小为PAGE_SIZE,用以存放一级表的指针
if (NewMidLevel == NULL) {
return NULL;
}
//
// If we need a new mid-level, we'll need a low-level too.
// We'll create one and if success we'll save it at the first position
//
NewLowLevel = ExpAllocateLowLevelTable( HandleTable, DoInit ); //申请一个一级表.
//有人问过为什么这个函数在申请二级表时同时还会申请一个一级表,看这个函数的调用时机就知道了.
//调用过程ExCreateHandle->ExpAllocateHandleTableEntry->ExpAllocateHandleTableEntrySlow->ExpAllocateMidLevelTable
//对ExCreateHandle更具体的分析,那是句柄分配的知识,稍后再说,以免偏题,现在只须知道调用ExpAllocateHandleTableEntrySlow时则表明句柄已达上限,需要再申请新的句柄表就行了
//而ExpAllocateHandleTableEntrySlow调用ExpAllocateMidLevelTable的第一个时机是TableLevel=0且句柄已达上限的时候,
//这时候需要申请这个二级表,那就说明一级表不够用了(三级表和二级表都只放指针,一级表中才是真正放内容的),需要再申请一个一级表,而两个一级表就使得句柄表的级数跃升为两级(MidLevel).所以,申请MidLevel的Table时其实就是稍带着把再申请一个一级表的工作也做好了(同样的,前面已经看到,申请HANDLE_TABLE时也是同时申请好了第一个一级表),这只是一级表跃升为二级表时的一个必做工作,仅此而已.总的说,二级表也只是框架,它有了内容(一级表)才能真正去放东西
//调用ExpAllocateMidLevelTable的另一种情况是此时TableLevel=2,但最后一个二级表已放满了.此时要申请一个一级表就需要先申请一个新的二级表,情况和前面类似了
if (NewLowLevel == NULL) {
ExpFreeTablePagedPool( HandleTable->QuotaProcess,
NewMidLevel,
PAGE_SIZE
);
return NULL;
}
//
// Set the low-level table at the first index
//
NewMidLevel[0] = NewLowLevel;//把这个新的一级表放入NewMidLevel[0],这个值后来则被放入了NewMidLevel[1],后面会分析到.而NewMidLevel[0]则存放最初的一级表(即升级为二级表之前的那个一级表),详细代码见ExpAllocateHandleTableEntrySlow()
*pNewLowLevel = NewLowLevel;
return NewMidLevel; //新的二级表地址作为返回值
}
句柄表的扩容:已分配的句柄表被用完时,ExpAllocateHandleTableEntrySlow被调用以分配一个新的句柄表,实现对句柄表的扩容.每次增加粒度都是一个一级表的大小(大小为PAGE_SIZE,句柄容量为PAGE_SIZE/sizeof(HANDLE_TABLE_ENTRY)*HANDLE_VALUE_INC=0x800),但是根据具体情况不同,表的结构可能会发生改变,可能只是增加了一个一级表,也有可能由一级升级为二级表等等,情况比较多.搞清这个函数的调用时机对于分析该函数的流程非常重要.
代码:
BOOLEAN
ExpAllocateHandleTableEntrySlow (
IN PHANDLE_TABLE HandleTable,
IN BOOLEAN DoInit
)
/*++
Routine Description:
This worker routine allocates a new handle table entry for the specified
handle table.
Note: The caller must have already locked the handle table
Arguments:
HandleTable - Supplies the handle table being used
DoInit - If FALSE then the caller (duplicate) doesn't need the free list built
Return Value:
BOOLEAN - TRUE, Retry the fast allocation path, FALSE, We failed to allocate memory
--*/
{
ULONG i,j;
PHANDLE_TABLE_ENTRY NewLowLevel;
PHANDLE_TABLE_ENTRY *NewMidLevel;
PHANDLE_TABLE_ENTRY **NewHighLevel;
ULONG NewFree, OldFree;
ULONG OldIndex;
PVOID OldValue;
ULONG_PTR CapturedTable = HandleTable->TableCode;
ULONG TableLevel = (ULONG)(CapturedTable & LEVEL_CODE_MASK); //当前句柄表的级数
PAGED_CODE();
//
// Initializing NewLowLevel is not needed for
// correctness but without it the compiler cannot compile this code
// W4 to check for use of uninitialized variables.
//
NewLowLevel = NULL;
CapturedTable = CapturedTable & ~LEVEL_CODE_MASK; //当前句柄表的基址
if ( TableLevel == 0 ) {//当前是一级表,这时再增加容量就需要升级为二级表了
//
// We have a single level. We need to ad a mid-layer
// to the process handle table
//
//分配一个二级表,ExpAllocateMidLevelTable的流程前面已经分析过了,它同时还分配了一个新的一级表,放在NewMidLevel[0]中
NewMidLevel = ExpAllocateMidLevelTable( HandleTable, DoInit, &NewLowLevel );
if (NewMidLevel == NULL) {
return FALSE;
}
//
// Since ExpAllocateMidLevelTable initialize the
// first position with a new table, we need to move it in
// the second position, and store in the first position the current one
//
NewMidLevel[1] = NewMidLevel[0]; //把刚申请到的一级表放入第二个位置
NewMidLevel[0] = (PHANDLE_TABLE_ENTRY)CapturedTable; //第一个位置存放CapturedTable,即最初的一级表
//之所以按这个顺序放置,是为了保证位置靠前的句柄表确实已经满载~
//
// Encode the current level and set it to the handle table process
//
CapturedTable = ((ULONG_PTR)NewMidLevel) | 1; //当前新的TableCode值,最低位置1,这是二级表的标志
OldValue = InterlockedExchangePointer( (PVOID *)&HandleTable->TableCode, (PVOID)CapturedTable );//设置新的TableCode值
} else if (TableLevel == 1) {//已经是二级表,则需要看具体情况是再分配一个一级表就可以了,还是可能升级为三级表
//
// We have a 2 levels handle table
//
PHANDLE_TABLE_ENTRY *TableLevel2 = (PHANDLE_TABLE_ENTRY *)CapturedTable;
//
// Test whether the index we need to create is still in the
// range for a 2 layers table
//
i = HandleTable->NextHandleNeedingPool / (LOWLEVEL_COUNT * HANDLE_VALUE_INC); //i是当前一级表的个数
if (i < MIDLEVEL_COUNT) { //若比二级表的最大容量小,则只需要再分配一个一级表(LowLevelTable)就可以了
//
// We just need to allocate a new low-level
// table
//
NewLowLevel = ExpAllocateLowLevelTable( HandleTable, DoInit ); //再申请一个一级表
if (NewLowLevel == NULL) {
return FALSE;
}
//
// Set the new one to the table, at appropriate position
//
OldValue = InterlockedExchangePointer( (PVOID *) (&TableLevel2[i]), NewLowLevel ); //放入二级表中
EXASSERT (OldValue == NULL);
} else {//已达到二级表最大数目,需要升级至三级表
//
// We exhausted the 2 level domain. We need to insert a new one
//
NewHighLevel = ExpAllocateTablePagedPool( HandleTable->QuotaProcess,
HIGHLEVEL_SIZE
);//申请一个表作为三级表
if (NewHighLevel == NULL) {
return FALSE;
}
NewMidLevel = ExpAllocateMidLevelTable( HandleTable, DoInit, &NewLowLevel );//给这个三级表申请一个二级表,至于为什么,原因前面分析ExpAllocateMidLevelTable时就分析过了,只不那是给二级表申请了一个一级表,道理是一样的~~
if (NewMidLevel == NULL) {
ExpFreeTablePagedPool( HandleTable->QuotaProcess,
NewHighLevel,
HIGHLEVEL_SIZE
);
return FALSE;
}
//
// Initialize the first index with the previous mid-level layer
//
NewHighLevel[0] = (PHANDLE_TABLE_ENTRY*)CapturedTable;//把原来的二级表地址放入三级表的第一个位置
NewHighLevel[1] = NewMidLevel; //刚申请的二级表放在第二个位置
//
// Encode the level into the table pointer
//
CapturedTable = ((ULONG_PTR)NewHighLevel) | 2; //设置TableCode低两位为2,即三级表的标志
//
// Change the handle table pointer with this one
//
OldValue = InterlockedExchangePointer( (PVOID *)&HandleTable->TableCode, (PVOID)CapturedTable );//设置新的TableCode
}
} else if (TableLevel == 2) {//当前已经是三级表了,情况分为三种:表全满,二级表满,一级表满
//
// we have already a table with 3 levels
//
ULONG RemainingIndex;
PHANDLE_TABLE_ENTRY **TableLevel3 = (PHANDLE_TABLE_ENTRY **)CapturedTable;
i = HandleTable->NextHandleNeedingPool / (MIDLEVEL_THRESHOLD * HANDLE_VALUE_INC); //三级表中二级表的个数
//
// Check whether we exhausted all possible indexes.
//
if (i >= HIGHLEVEL_COUNT) { //二级表个数超出三级表的容易则失败!(实际上达不到这个数)
return FALSE;
}
if (TableLevel3[i] == NULL) { //确定这个位置可用,还没有放置二级表指针, 这也表明需要申请一个新的二级表了
//
// The new available handle points to a free mid-level entry
// We need then to allocate a new one and save it in that position
//
NewMidLevel = ExpAllocateMidLevelTable( HandleTable, DoInit, &NewLowLevel );//申请一个二级表
if (NewMidLevel == NULL) {
return FALSE;
}
OldValue = InterlockedExchangePointer( (PVOID *) &(TableLevel3[i]), NewMidLevel );//放入刚才的位置
EXASSERT (OldValue == NULL);
} else { //若TableLevel3[i]不为NULL,则表明TableLevel3[i]这个二级表已存在,但还没有放满,只需要给这个二级表再申请一个一级表就可以了
//
// We have already a mid-level table. We just need to add a new low-level one
// at the end
//
RemainingIndex = (HandleTable->NextHandleNeedingPool / HANDLE_VALUE_INC) -
i * MIDLEVEL_THRESHOLD;
j = RemainingIndex / LOWLEVEL_COUNT;//计算出新的一级表在TableLevel3[i]这个二级表中的偏移
NewLowLevel = ExpAllocateLowLevelTable( HandleTable, DoInit ); //只需要申请一个一级表
if (NewLowLevel == NULL) {
return FALSE;
}
OldValue = InterlockedExchangePointer( (PVOID *)(&TableLevel3[i][j]) , NewLowLevel );//把刚申请的一级表放入TableLevel3[i]这个二级表中
EXASSERT (OldValue == NULL);
}
}
//
// This must be done after the table pointers so that new created handles
// are valid before being freed.
//
OldIndex = InterlockedExchangeAdd ((PLONG) &HandleTable->NextHandleNeedingPool,
LOWLEVEL_COUNT * HANDLE_VALUE_INC);//设置新的NextHandleNeedingPool,增量为一个一级句柄表的句柄容量(即一级表中HANDLE_TABEL_ENTRY的个数再乘4),并把原来的NextHandleNeedingPool值放入OldIndex,也就是说,OldIndex是曾经的句柄值上限
if (DoInit) {//这里对刚申请的一级表进行一些初始化工作
//
// Generate a new sequence number since this is a push
//
OldIndex += HANDLE_VALUE_INC + GetNextSeq();//GetNextSeq()的结果为0,所以相当于只加了一个HANDLE_VALUE_INC,即4,此时的OldIndex是新分配的句柄表中的最小句柄
//
// Now free the handles. These are all ready to be accepted by the lookup logic now.
//
while (1) {
OldFree = ReadForWriteAccess (&HandleTable->FirstFree); //OldFree是原来的FirstFree的值
NewLowLevel[LOWLEVEL_COUNT - 1].NextFreeTableEntry = OldFree; //把一级表的最后一项的NextFreeHandle指向以前的HandleTable->FirstFree, 这就相当于把原来的FreeHandleList连在了新申请的句柄表的FreeHandleList链后面,成为一条新的FreeHandleList
//
// These are new entries that have never existed before. We can't have an A-B-A problem
// with these so we don't need to take any locks
//
NewFree = InterlockedCompareExchange ((PLONG)&HandleTable->FirstFree,
OldIndex,//用为新的FirstFree的值放入,新申请的句柄将从这个值开始
OldFree);
if (NewFree == OldFree) {//成功,就跳出这个循环了
break;
}
}
}
return TRUE;
}
句柄表的释放比较简单,遍历并释放每个一级表所占内存就可以了~
VOID
ExpFreeHandleTable (
IN PHANDLE_TABLE HandleTable
);
1.计算TableLevel和顶层表的基址CapturedTable
2.按TableLevel不同进行不同处理~
TableLevel=0,一级表时:直接Free掉即可
f (TableLevel == 0) {
//
// There is a single level handle table. We'll simply free the buffer
//
PHANDLE_TABLE_ENTRY TableLevel1 = (PHANDLE_TABLE_ENTRY)CapturedTable;
ExpFreeLowLevelTable( Process, TableLevel1 );
//TableLevel=1,二级表时,稍有不同,但也只是依次遍历判断然后释放掉:
if (TableLevel == 1) {
//
// We have 2 levels in the handle table
//
PHANDLE_TABLE_ENTRY *TableLevel2 = (PHANDLE_TABLE_ENTRY *)CapturedTable;
for (i = 0; i < MIDLEVEL_COUNT; i++) {
//
// loop through the pointers to the low-level tables, and free each one
//
if (TableLevel2[i] == NULL) {
break;
}
ExpFreeLowLevelTable( Process, TableLevel2[i] );
}
//
// Free the top level table
//
ExpFreeTablePagedPool( Process,
TableLevel2,
PAGE_SIZE
);
}
//TableLevel=2,三层表时,处理过程类似,遍历每个二级表,然后释放之
else {
//
// Here we handle the case where we have a 3 level handle table
//
PHANDLE_TABLE_ENTRY **TableLevel3 = (PHANDLE_TABLE_ENTRY **)CapturedTable;
//
// Iterates through the high-level pointers to mid-table
//
for (i = 0; i < HIGHLEVEL_COUNT; i++) {
if (TableLevel3[i] == NULL) {
break;
}
//
// Iterate through the mid-level table
// and free every low-level page
//
for (j = 0; j < MIDLEVEL_COUNT; j++) {
if (TableLevel3[i][j] == NULL) {
break;
}
ExpFreeLowLevelTable( Process, TableLevel3[i][j] );//依次释放最底层的一级表
}
ExpFreeTablePagedPool( Process,
TableLevel3[i], //释放这个二级表所占的内存
PAGE_SIZE
);
}
//
// Free the top-level array
//
ExpFreeTablePagedPool( Process,
TableLevel3, //最后,释放三级表所占内存,级别从低到高
HIGHLEVEL_SIZE
);
}