Т» јДґжЖч(Registers)
1. НЁУГДїµДјДґжЖч
r0µЅr127µДјДґжЖч,Т»№І128ёц,З°32ёцr0µЅr31КЗѕІМ¬µД,r1±ЈґжИ«ѕЦЦёХл(gp),r12±ЈґжХ»ЦёХл(sp),ГїёцјДґжЖчКЗ64О»µДїн¶И,r32µЅr127КЗ¶ЇМ¬µД,Т»№І96ёц;
ХвАпЛщОЅµДѕІМ¬КЗЦёr0µЅr31ЧЬКЗЦёПт№М¶ЁµДCPUОпАнјДґжЖч,ЛщОЅµД¶ЇМ¬КЗЦёёш¶ЁјДґжЖчІў·ЗЧЬКЗТэУГЧјИ·ПаН¬µДCPUОпАнјДґжЖч

јДґжЖчёДГыКЗCPUґпµЅМбЙэРВДЬДї±кµД»щ±ѕТтЛШ
ЖдКµ¶ЇМ¬јДґжЖчєНCPUµДОпАнјДґжЖчЦ®јдµД¶ФУ¦ФЪєЇКэДЪІ»»б·ўЙъ±д»ЇµДЈ¬јДґжЖчёДГыЅцЅцКЗїШЦЖБчґУТ»ёцєЇКэµЅБнТ»ёцєЇКэµДК±єтІЕ·ўЙъ
IA-64µДГїТ»јюКВЗйµДОЁТ»µДДї±кѕНКЗЛЩ¶И,ЛщТФФЪ64О»ПµНіЦРІОКэКЗНЁ№эХвР©јДґжЖчґ«µЭёш±»µчУГєЇКэµД,±ИЖрX86ґУТ»ёцЅПВэµДЦчДЪґжЦР¶БІОКэТЄїмєЬ¶аЈ¬ТтОЄєуХЯРиТЄ»Ё·С12ёцК±ЦУЦЬЖЪЈ¬¶шЗ°ХЯЅцЅцРиТЄ1ёцК±ЦУЦЬЖЪ
¶ЇМ¬јДґжЖчµДґжФЪК№µГєЇКэДЬУРУµУРЧФјєёЯґп96ёцјДґжЖчјЇК№УГ,r32µЅr127КЗ±ЈБфёшєЇКэДЪК№УГµД,єЇКэµДѕЦІї±дБїєНІОКэ¶ј±ЈґжФЪХв96ёцјДґжЖчЦР,µ«Іў·ЗГїґО¶јУГНкХвГґ¶ајДґжЖч
ХвАпѕНУРБЛ·ЗіЈЖж№ЦµДКВЗйБЛ,ГїёцєЇКэ¶јО¬іЦХвёц96ёцјДґжЖч,ДЗГґЧУєЇКэ±»µчУГµДК±єт»бФхГґСщДШ,КВКµКЗ,ёёєЇКэІўГ»УР±Јґжµ±З°µД96ёцјДґжЖчµДДЪИЭ,І»КЗ°ЙЈ¬ХвСщТІРР,µ«КЗИ·КµКЗХжµД,ФЪIA-64ЦРУРТ»ёц±ИЅПЖжГоµД¶«Оч---јДґжЖчХ»ТэЗж(Register Stack Engine)Ј¬ХвКЗIA-64µДТ»ёц·ЗіЈБЛІ»ЖрµДМШРФ,ЖдЦРµДФАн»№І»М«Зеію,ФЪХвАпЦШТЄµДКЗјЗЧЎr32µЅr127¶ФУЪГїёцєЇКэ¶јКЗП໥¶ФБўµД,ХвѕНПсwin32К±єтіцПЦµДЅшіМУРёчЧФП໥¶АБўµДµШЦ·їХјд
2. ёЎµгКэјДґжЖч
f0µЅf127,ЧЬјЖ128ёц,ёЎµгКэјДґжЖч±ЈґжѕНПсC++ДЗСщµДі¤Л«ѕ«¶ИЦµ,УлХыРНµДјДґжЖчТ»Сщ,ДіР©ёЎµгКэјДґжЖчТІУРФ¤¶ЁТеµД·ЅКЅ,f0ЧЬКЗЙиЦГОЄ0.0,f1ЧЬКЗЙиЦГОЄ1.0
3. ·ЦЦ§јДґжЖч
b0µЅb7,Т»№І8ёц, ХвР©јДґжЖч±ЈґжБЛCPUЅ«їШЦЖґ«µЭµЅДіёцО»ЦГґъВлµДµШЦ·,ФЪIA-64ЦРЈ¬ЛщУРµДїШЦЖґ«Кд¶јКЗТФ·ЦЦ§јДґжЖчµДРОКЅґжФЪµД.
ФЪIA-64ЦР,br.callЦёБоПа¶ФУЪX86µДCALL,br.retПа¶ФУЪX86µДRET,brѕНКЗX86µДЦРJMP
ХвР©ЦёБоµДІЩЧчКэІ»ДЬПсX86ДЗСщКЗИОТвµДДЪґжµШЦ·,±ШРлКЧПИЅ«µШЦ·јУФШЅш·ЦЦ§јДґжЖчЦР,ИфІ»КЗХвСщ,ХвР©ІЩЧчКэТІКЗПа¶ФУЪЦёБоЦёХлµДµШЦ·
¶ю №эіМЦЎ,ІОКэґ«µЭ,јДґжЖчХ»ТэЗж(Resgister Stack Engine)
1. №эіМЦЎ
96ёц¶ЇМ¬јДґжЖч±»»®·ЦЦёПтІ»Н¬µДЗшУт,Input,Local,Output

ХэИзНјЦРЛщКѕµДДЗСщ,ІОКэНЁ№эInput registersґ«µЭµД,ѕЦІї±дБїєН±аТлЖчБЩК±±дБїКЗНЁ№эLocal registersґ«µЭµД,Output registers±ЈґжБЛµчУГПВТ»ёцМбЗ°Чј±ёєГµДєЇКэµДІОКэ,±аТлЖчѕц¶ЁБЛ¶ФУЪТ»ёцМШ±рµДєЇКэРиТЄ¶аЙЩInput,local,outputјДґжЖч,ФЪєЇКэµДФ¤ґ¦АнІї·Ц,±аТлЖч·ЕЦГТ»ёцallocЦёБо·ЦЕдЛщРиКХИл,±ѕµШ,КдіцµДјДґжЖчКэБї,¶ФУЪКдіцЗшУтµДґуРЎ,±аТлЖчК№УГЦчєЇКэµчУГЧУєЇКэµДЧоґуІОКэКэБї,КµјКµДКдіцјДґжЖчµДґуРЎКЗ°ЛёцјДґжЖч»тХЯёьЙЩ
br.callµчУГЦ®єу96ёц¶ЇМ¬јДґжЖчЅ«±»ёДГы,¶шЗТCFMТІ»б±»ёьРВµД,ФЪµчУГєЇКэµДК±єтoutputyouУРІ»Н¬µДГыЧЦ,ФЪbr.callµчУГЦ®З°КдіцјДґжЖчКЗr41µЅr46,µчУГЦ®єуЅ«ёДГыОЄr32µЅr37

ДЗГґµ±ЧУєЇКэ·µ»ШТФєу»б»№ФЦ®З°µДјДґжЖчВрЈ¬ХвАпѕНУРБЛar.pfs,ЧчОЄcallЦёБоµДТ»Ії·Ц,CPUЅ«µ±З°µДCFMјДґжЖчµДЦµёґЦЖµЅar.pfsЦР,ФЪєЇКэµчУГЦ®єу,РВµДєЇКэКЗГ»УРКдИлєНѕЦІїјДґжЖчµД,¶шЗТКдіцјДґжЖчЦР±ЈґжБЛґУёёєЇКэґ«µЭ№эАґµДІОКэ,allocФЪХвАпЧцТ»Р©ґЫёДРРОЄ,Ц®З°єЇКэµДКдјДґжЖч·ЦіЙБЛРВєЇКэµДКдИлјДґжЖч,И»єуallocОЄРВµДєЇКэЅЁБўРВµДѕЦІїєНКдіцјДґжЖч,Чоєуalloc±Јґжar.pfsµЅТ»ёцНЁУГДїµДјДґжЖчАпГж,allocЦёБоК№УГµДАэЧУИзПВ:
alloc r36 = ar.pfs, 0x7, 0x0, 0x2, 0x0
ХвМхЦёБоЅЁБўБЛТ»ёцЦЎ,К№УГБЛЖЯёцКдИлКдИлјДґжЖчЧчОЄКдИлЗшУт,БгёцѕЦІїјДґжЖч,БЅёцКдіцјДґжЖчЧчОЄКдіцЗшУт,ЧоєуДЗёцБгКЗїЙТФєцКУµД,ar.fps±»±ЈґжµЅБЛr36ЦР,ТФєуЅЁБўРВµДКдИлЈ¬ѕЦІїєНКдіцјДґжК±єтТэУГ
2. ІОКэґ«µЭ
ІОКэїЙДЬНЁ№эНЁУГДїµДјДґжЖч,ёЎµгКэјДґжЖчєНПЯіМХ»ЦРґ«µЭ,ХвАпУРТ»ёцІОКэІЫµДёЕДо,ЛьµДі¤¶ИКЗ°ЛЧЦЅЪїн,µ«КЗКµјКµДІОКэµДі¤¶ИКЗУЙІОКэ±ѕЙнµДАаРНѕц¶ЁµД,ёЎµгКэІОКэТ»°гК№УГf8µЅf15µДёЎµгКэјДґжЖчЅшРРґ«µЭµД,ИОєОІОКэі¬№э°ЛёцІОКэІЫЅ«±»±ЈґжµЅХ»ЦР,Из№ыКдИлµДІОКэјґУРХыРНКэ,УЦУРёЎµгКэЈ¬УРР©КВЗй±дµДёьјУµДёґФУ,ФЪХвАпІОКэІЫєННЁУГДїµДКдіцјДґжЖчУРЧЕТ»Т»¶ФУ¦µД№ШПµ,Из№ыёЎµгКэ±»УіЙдµЅМШ±рµДІОКэІЫЦР,ДЗГґКдіцјДґжЖчЅ«ТЄ±»УіЙдµЅГ»УР±»К№УГµДІОКэІЫ,АэЧУИзПВЈє
SomeOtherFunction(void)
{
int x = 1, y = 2;
float fpv1 = 1.2, fpv2 = 3.4;
BarFunction( x, fpv1, fpv2, y );
}
void BarFunction( int a, float b, float c, int d )
{
}
r40 = x r41 = ? // unused r42 = ? // unused r43 = y f8 = fpv1 f9 = fpv2
3. єЇКэ·µ»Ш
IA-64¶ФУЪИОТвµД·ыєП°ЛЧЦЅЪ»тХЯёьРЎµДЧЦЅЪµДХыРНКэ±ЈґжµЅr8јДґжЖчЦР, r8ѕНПаµ±УЪX86ЦРµДEAX,¶ФУЪґуУЪ°ЛЧЦЅЪµДХыРН·µ»ШЦµїЙТФК№УГr8µЅr11µДјДґжЖч,ёЎµгРНµД·µ»ШЦµТ»°гНЁ№эf8·µ»Ш,Из№ы·µ»ШЦµі¬№эБЛµҐёцr8ДЬ±нКѕµД·¶О§,ЛьЅ«їЙТФК№УГf8µЅf11µДёЎµгКэјДґжЖч;ФЪX86ЦР·µ»ШµШЦ·ФЪµчУГЧУєЇКэµДК±єтТСѕМбЗ°±»±ЈґжµЅБЛХ»ЦР,µ«КЗФЪIA64ЦР,Х»ЦРёь±ѕГ»УР±Јґж·µ»ШµШЦ·,¶шКЗФЪ·ЦЦ§јДґжЖчАп,їјВЗИзПВЦёБо:
br.call.dptk.many b0 = b6
qptk.mangКЗbr.callµДТ»Ії·ЦЈ¬ФЪХвАпІўІ»КЗЦШТЄµДЈ¬b6±ЈґжБЛcallµДПВТ»МхЦёБоµДµШЦ·,ЧЬЦ®,·µ»ШµШЦ·Т»°г±»±ЈґжФЪb0ЦР,µ«КЗФЪЅшИл±»µчУГєЇКэДЪ,b0µДЦµТЄ±»±ЈґжНЁУГДїµДјДґжЖчЦР,ТтОЄ±»µчУГєЇКэ»№µчУГЖдЛыµДЧУєЇКэЈ¬Из№ыb0І»БЩК±µД±ЈґжµЅЖдЛыµДјДґжЖчЦРµД»°,ЛьµДЦµУРїЙДЬ±»ПВТ»ёцЧУєЇКэµД·µ»ШµШЦ·ёІёЗ,ФЪЧУєЇКэНЁ№эbr.ret·µ»ШµЅµчУГєЇКэµДК±єт,іэБЛТЄЙиЦГ·µ»ШµШЦ·јДґжЖчНв,»№ТЄёД±д№эіМЦЎєНјДґжЖчГыЧЦµЅµчУГєЇКэµДЧґМ¬,ХвёцК±єтТює¬µДТ»ёцІЩЧчКЗar.pfsТЖ¶ЇµЅCFMјДґжЖч3. јДґжЖчХ»ТэЗж(The Register Stack Engine)RSEКЗIA-64ЦР·ЗіЈЦШТЄµДТ»ёцМШРФ,У¦УГіМРтёь±ѕІ»ЦЄµАЛьµДґжФЪТФј°ЛьКЗИзєО№¤ЧчµДЈ¬КµјКЙП,ЛьёьПсТ»ёцєуМЁУІјюПЯіМ,ХвёцПЯіМЅ«¶БИЎєНРґИл¶ЇМ¬µДјДґжЖчµЅНвІїµДДЪґжЦРЈ¬ХвёцДЪґжКЗОЄТФєу»Цёґ¶шК№УГµД,ІўЗТІЩЧчПµНіёєФрОЄЛь·ЦЕдДЪґж,ХвАпУРТ»ёц·ЦЕдФФт,З¶МЧФЅЙоµДєЇКэµДјДґжЖч,ЧоРВФЅЙЩК№УГµД±»РґИлДЪґж,ХвСщїЙТФКН·ЕµфХвР©І»іЈУГµДјДґжЖчОЄРВµДµчУГК№УГ,ХвАпУРТ»¶ФјДґжЖчar.bspєНar.bspstore±ЈґжБЛЦ®З°±»ТзіцµЅДЪґжµДјДґжЖчµД№мјЈ,µ±єЇКэ·µ»ШµДК±єт,RSEЦЄµАЦШРВјУФШЦ®З°±ЈґжФЪДЪґжЦРµДјДґжЖч,ХвАпТЄёгЗеіюТ»ёцТ»Т»¶ФУ¦µД№ШПµ,ФЪєЇКэЦЎЦРµДјДґжЖчєН±ЈґжФЪДЪґжЦРТС±»ИХєу»ЦёґµДјДґжЖч
Иэ И«ѕЦЦёХл(Global Pointer)
1. И«ѕЦЦёХл
КЗМбЗ°Цё¶ЁµД·ГОКТ»ёцјУФШДЈїйДЪКэѕЭµДЦµ,ХвёцЦёХлФЪX86ЦРКЗГ»УР±ШТЄµД,ТтОЄ¶ФУЪ32О»(4GB)µДЦёБоЧгТФИЭДЙ32О»µДµШЦ·іЙОЄ±аВлµДТ»Ії·Ц,АэИз:
MOV ECX,[0x12345678]
ХвёцЦёБоТ»№ІХјБЛБщёцЧЦЅЪ,MOV ECXХјБЅёцЧЦЅЪ,КЈПВµДЛДёцЧЦЅЪКЗЛ«ЧЦµДµШЦ·----24О»
ФЪIA-64ЦР,ГїёцЦёБоµДі¤¶ИКЗ41О»,ДЗГґ±Јґж64О»µДµШЦ·КЗІ»їЙДЬµД,ЛщТФЛщУРµДДЪґж·ГОК±ШРлНЁ№эјУФШНЁУГДїµДјДґжЖчµДЦёХлЦµІЕїЙТФ,¶ФУЪГїТ»ёц»щУЪIA-64µДјУФШДЈїй¶јТ»ёцИ«ѕЦЦёХлЦµ,ХвёцЦµЦёПтјУФШДЈїйѕІМ¬КэѕЭЗшУтёЅЅь,ХвР©КэѕЭ°ьАЁ,И«ѕЦ±дБї,ЧЦ·ыґ®,COMРйєЇКэ±н,ЖдЛыёчЦЦПоДї,¶ФУЪµ±З°µДјУФШДЈїйИ«ѕЦЦёХлµДЦµКЗ±»јУФШµЅr1ЦРµД,ФЪ·ґ»г±а№¤ѕЯєНµчКФЖчЦР,ОЄБЛјЗТдµД·Ѕ±г,r1НЁіЈ±»БнТ»ёцГыЧЦТэУГµД,GPјДґжЖч
јУФШДЈїйµДКэѕЭЗшУт±»ПЮЦЖОЄ4MB,ТтОЄФЪIA-64µДТ»ёцМхµҐЦёБоДЬ±»ФцјУµЅјДґжЖчµДЧоґуБўјґКэКЗ22О»,јЖЛгТ»ПВДг»б·ўПЦ22О»ТэУГ4MBµДДЪґжґуРЎ
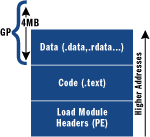
јёєхЛщУРµДјУФШДЈїйµДКэѕЭКЗПа¶ФУЪGP±аЦ·µД,ЛщТФЦёБоЦРГ»УР°ьє¬ИОєОУІ±аВлµДµШЦ·,І»ПсX86ѕіЈРиТЄДЗСщЧц,ґъВлКЗІ»ТААµУЪО»ЦГµД,ГїґОФЪДЪґжјУФШТ»ёцµШЦ·КЗІ»РиТЄРЮёДОЄХэИ·µДЦµ,»щ±ѕПыіэБЛX86ПµНіЙПµД»щЦ·ЦШµШО»»ъЦЖ
ДЗГґі¬№э4MBµДКэѕЭёГИзєОґ¦АнДШ,ХвѕНєН±аТлЖчУР№ШБЛ,ФЪЅПРЎµДКэѕЭЗшУтґжґўБЛТ»ёцЦёПтґуДЪґжЗшУтµДЦёХл,±аТлЦЄµАКІГґК±єтјдЅУµДНЁ№эТ»ёцЦёХлµГµЅґуДЪґжЗшУтµДµШЦ·,ФзФЪ1992Дкwin32ѕН°ьє¬БЛХвёцЦёХлµД¶ЁТе,ФЪWINNT.HАпїЙТФІйµЅ#define IMAGE_DIRECTORY_ENTRY_GLOBALPTR
И«ѕЦЦёХлµДЙиЦГКЗФЪµчУГCALLµДК±єт·ўЙъµД,ТІѕНКЗёёєЇКэёєФрЙиЦГХэИ·µДИ«ѕЦЦёХлЦµ,ХвёцЦµ±ЈґжФЪТ»ёцIntelМбЗ°¶ЁТеµДКэѕЭївЅб№№ЦР,КЗѕ№эОўИнН¬ТвОЄБЛКµПЦ64О»ПµНі
2. ЅйЙЬPLEBAL_DESCRIPTOR
ФЪОўИнµДVisual Studio 6.0µДWINNT.HїЙТФХТµЅ¶ФХвёцЅб№№µД¶ЁТе:
typedef struct _PLABEL_DESCRIPTOR {ULONGLONG EntryPoint;ULONGLONG GlobalPointer;} PLABEL_DESCRIPTOR, *PPLABEL_DESCRIPTOR;

void foo(void)
{
}
void main()
{
void * p = &foo;
}
ХвАпМщЙПОўИнMATTµДАэЧУ:
#define WIN32_LEAN_AND_MEAN
#include <windows.h>
#include <stdio.h>
#ifndef _M_IA64
#error "This program only runs on an IA64 system\n" );
#endif
PVOID GetGlobalPointerFromHMODULE( HMODULE hModule );
int main()
{
// Get the "address" of function main(). This address is really
// a PLABEL_DESCRIPTOR, defined in WINNT.H
PLABEL_DESCRIPTOR * pLabelDesc = (PLABEL_DESCRIPTOR *)&main;
// Print out the PLABEL_DESCRIPTOR fields
printf( "EntryPoint: %p\n", pLabelDesc->EntryPoint );
printf( "GlobalPointer: %p\n", pLabelDesc->GlobalPointer );
// Just for fun, find out and display the GlobalPointer of this EXE,
// using the RVA stored in the PE header. This GlobalPointer should
// match the GlobalPointer from above.
HMODULE hModule = GetModuleHandle( 0 ); // Get HMODULE of this
// program
PVOID globalPointer = GetGlobalPointerFromHMODULE( hModule );
printf( "GlobalPointer from PE header: %p\n", globalPointer );
return 0;
}
// MakePtr is A handy macro function for creating pointers of the
// appropriate type. It adds the two values as integral types, and cast
// the result to the desired pointer type
#define MakePtr(cast, ptr, addValue) \
(cast)((DWORD_PTR)(ptr) + (DWORD_PTR)(addValue))
PVOID GetGlobalPointerFromHMODULE( HMODULE hModule )
{
// Point to the "DOS" header so that we can locate the "PE" header
PIMAGE_DOS_HEADER pDosHdr = (PIMAGE_DOS_HEADER)hModule;
// Make a pointer to the PE32+ header
PIMAGE_NT_HEADERS pNTHdr = MakePtr( PIMAGE_NT_HEADERS,
hModule,
pDosHdr->e_lfanew );
// Get the RVA of the GlobalPointer from the PE's DataDirectory
DWORD gpRVA = pNTHdr->OptionalHeader.DataDirectory
[IMAGE_DIRECTORY_ENTRY_GLOBALPTR].VirtualAddress;
// Add the RVA to the module load address to form the GlobalPointer
// address
return MakePtr( PVOID, hModule, gpRVA );
}
ІОїј:
http://www.intel.com/design/
http://msdn.microsoft.com/zh-cn/maga...11(en-us).aspx
http://msdn.microsoft.com/zh-cn/maga...17(en-us).aspx