《去除“HTML Help Workshop”反编译功能中的Bug》
相关下载
天津 赵春生
“HTML Help Workshop”是MS出品的一款用来制作CHM文件的软件(简称HHW),手头儿的版本是4.74.8702.0,自带反编译功能,但在使用的过程中发现此功能无法正确处理文件名中含有Unicode宽字节字符串的文件,并且“CHM Information”功能也有同样的问题。
一:Bug形成的原因:
为了方便调试,我制作了一个“test.chm”,其中包含三个文件:“index.htm”,“1.htm”,“测试文件1.htm”。其中“index.htm”对其余两个文件有超链接引用,这样该CHM文件中就存在了文件名中含有Unicode宽字节字符串的文件――“测试文件1.htm”。分别执行“Decompile”和“CHM Information”,发现文件“测试文件1.htm”都没有被正确处理,但从“CHM Information”的LOG中发现其文件大小已被正确获取。见下图(1):
一个大胆的推测:这两个功能的Bug源于同一个程序模块。
用OLLYDBG加载“hhw.exe”,发现调用了API“CreateFileA”,设上断点并开始执行“Decompile”功能,OLLYDBG中断后可以看到程序即将创建反编译出来的文件,并且紧接着就是API“WriteFile”的调用,随后程序跳到上面的代码继续处理下一个文件……经过艰苦地跟踪,发现0042F88D调用了“hha.dll”空间中的代码,F7进去后惊喜地发现了出现Bug的原因,现以“测试文件1.htm”为例进行说明:
4530FA4F CALL DWORD PTR DS:[<&KERNEL32.lstrlenW>]//返回值为9,没错
4530FA55 MOV EBP,EAX
4530FA57 LEA EAX,DWORD PTR SS:[EBP+1]
4530FA5A PUSH EAX
4530FA5B CALL HHA.45341D70
4530FA60 POP ECX
4530FA61 MOV ESI,EAX
4530FA63 PUSH EBX //参数8
4530FA64 PUSH EBX //参数7
4530FA65 PUSH EBP //参数6 传递了错误的参数!
4530FA66 PUSH ESI //参数5
4530FA67 PUSH EBP //参数4
4530FA68 MOV DWORD PTR DS:[EDI],ESI
4530FA6A PUSH DWORD PTR SS:[ESP+28] //参数3
4530FA6E PUSH EBX //参数2
4530FA6F PUSH EBX //参数1
4530FA70 CALL DWORD PTR DS:[<&KERNEL32.WideCharToMultiByte>]//将宽字符串转换成多字节字符串
4530FA76 MOV BYTE PTR DS:[EAX+ESI],BL //添'0',最终形成多字节字符串
先来看看API(lstrlenW):
“测试文件1.htm”的Unicode码为:
[4B 6D D5 8B 87 65 F6 4E 31 00 2E 00 68 00 74 00 6D 00]
ANSI码为:
[B2 E2 CA D4 CE C4 BC FE 31 2E 68 74 6D]
执行API(lstrlenW)的返回值为0x9,因为该API返回Unicode码字符长度且不包括字符串结束符'0',完全正确。
再看看API(WideCharToMultiByte):
int WideCharToMultiByte(
UINT CodePage, // code page
DWORD dwFlags, // performance and mapping flags
LPCWSTR lpWideCharStr, // address of wide-character string
int cchWideChar, // number of characters in string
LPSTR lpMultiByteStr, // address of buffer for new string
int cchMultiByte, // size of buffer
LPCSTR lpDefaultChar, // address of default for unmappable characters
LPBOOL lpUsedDefaultChar // address of flag set when default char. used
);
Return Values:
If the function succeeds, and cchMultiByte is nonzero, the return value is the number of bytes written to the buffer pointed to by lpMultiByteStr.
If the function succeeds, and cchMultiByte is zero, the return value is the required size, in bytes, for a buffer that can receive the translated string.
If the function fails, the return value is zero.
当前程序执行到4530FA70时,堆栈显示如下:
0012F3E4 00000000 CodePage = CP_ACP
0012F3E8 00000000 Options = 0
0012F3EC 001673D0 WideCharStr = "测试文件1.htm"
0012F3F0 00000009 WideCharCount = 9
0012F3F4 00970D90 MultiByteStr = 00970D90
0012F3F8 00000009 MultiByteCount = 9 //错误的参数!应为0xD
0012F3FC 00000000 pDefaultChar = NULL
0012F400 00000000 pDefaultCharUsed = NULL
注意看参数MultiByteCount=9,对应SDK里的说明:“int cchMultiByte, //size of buffer”,在这里,该值应为0xD,为什么呢?因为“测试文件1.htm”的ANSI码为:[B2 E2 CA D4 CE C4 BC FE 31 2E 68 74 6D],一共13个字节。试着将堆栈中的参数修改,程序正确执行,“Decompile”和“CHM Information”功能正常工作!
程序员在这里犯了两个小小的错误:其一:错误地将cchWideChar的值传递给了cchMultiByte,cchMultiByte的大小决定了转换成多字节字符串所需的缓冲区大小,本来13个字节的内容非要写进9个字节空间中去,如此一来,API执行失败,返回了'0'――EAX;其二:没有判断API的返回值,紧接着就执行了MOV BYTE PTR DS:[EAX+ESI],BL,这样可好,原本9个字节空间中的内容已经面目全非了,还要在头上砸一个鸭蛋'0'――形成了一个彻底的空串,从而出现图(1)那样的情况。
二:SMC:
正确获取cchMultiByte的值并将其传递给API(WideCharToMultiByte)函数是消除本程序Bug的关键,翻看SDK手册得知:当cchMultiByte=0时,API(WideCharToMultiByte)将返回目标所需缓冲区的大小值……这样一来,我们可以自己构造函数参数,在得到正确的cchMultiByte后,再执行字符串的转换工作。
在“hha.dll”空间下面找出一块儿空白区用来存放我们的代码:
45362D60 PUSHAD
45362D61 PUSH 0 //lpUsedDefaultChar
45362D63 PUSH 0 //lpDefaultChar
45362D65 PUSH 0 //cchMultiByte=0,这样就能返回目标所需缓冲区的大小值了
45362D67 PUSH 0 //lpMultiByteStr,不需要在缓冲区中写东西,地址设0就行
45362D69 PUSH EBP //cchWideChar=EBP,API(lstrlenW)的返回值
45362D6A PUSH DWORD PTR SS:[ESP+3C] //lpWideCharStr,Unicode字符串地址
45362D6E PUSH 0 //dwFlags
45362D70 PUSH 0 //CodePage,CP_ACP=0
45362D72 CALL DWORD PTR DS:[<&KERNEL32.WideCharToMultiByte>] //返回所需缓冲区的大小
45362D78 MOV DWORD PTR DS:[45362DA6],EAX //将所需缓冲区的大小保存到DS:[45362DA6]
45362D7D POPAD
45362D7E ADD ESP,18 //调整栈指针,移动到原来cchMultiByte参数的位置上
45362D81 PUSH DWORD PTR DS:[45362DA6] //将所需缓冲区的大小入栈,形成新的cchMultiByte参数
45362D87 SUB ESP,14 //调整栈指针,移动到栈顶,既第一个参数的位置
45362D8A CALL DWORD PTR DS:[<&KERNEL32.WideCharToMultiByte>] //开始转换
45362D90 JMP HHA.4530FA76 //返回原程序
45362D95 NOP
然后修改下面的代码使之跳转到我们的代码中:
4530FA70 CALL DWORD PTR DS:[<&KERNEL32.WideCharToMultiByte>]
改为:
4530FA70 JMP HHA.45362D60
4530FA75 NOP //补位
因为我们的SMC代码需要向DS:[45362DA6]中写入内容,所以需要把该代码段所处的[.text]节改为可写,用LordPE即可。见下图(2):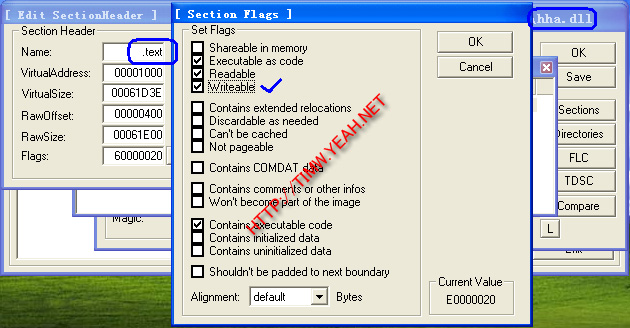
现在,修改后的程序已经能正确处理文件名中含有Unicode宽字节字符串的文件了,下图(3)为执行“CHM Information”后的效果图:
《去除“HTML Help Workshop”反编译功能中的Bug》修
经过反复地测试,又在“hha.dll”中找到了一个Bug,见以下代码:
4530FA4F CALL DWORD PTR DS:[<&KERNEL32.lstrlenW>] //kernel32.lstrlenW
4530FA55 MOV EBP,EAX
4530FA57 LEA EAX,DWORD PTR SS:[EBP+1]
4530FA5A PUSH EAX
4530FA5B CALL HHA.45341D70 //得到ANSI字符串存放地址――问题出现!
4530FA60 POP ECX //执行后ECX为Unicode字符串个数+1
4530FA61 MOV ESI,EAX //将用来存放转化后的ANSI字符串地址EAX传递给ESI
4530FA63 PUSH EBX
4530FA64 PUSH EBX
4530FA65 PUSH EBP
4530FA66 PUSH ESI //ANSI字符串存放地址作为参数入栈
问题在于4530FA5B这段代码,这段代码得到的地址可能会与我们指定的[Destination folder]在内存中的地址冲突([Destination folder]:指定存放反编译出来的文件的存放地址,如:“C:\temp”),从而导致以下问题的产生:文件存放路径和文件名被转换后的ANSI字符串破坏掉,从而使得创建文件时失败……实践证明这种几率很大!不知道这个Bug和上次的程序修改是否有关……
解决的方法有两个:1:改变反编译出来的文件的存放地址在内存中的位置;2:改变转换后的ANSI字符串在内存中的存放地址。相比起来后者较为简单,因为所有的SMC代码都可以放在“hha.dll”中。
修改4530FA61这段代码,使之跳转到一个空白区45362D50,该区域的代码用来实现将指定的ANSI字符串的存放地址交给ESI寄存器:
4530FA61 JMP HHA.45362D50 //跳转到45362D50
45362D50 MOV ESI,HHA.45362DA8 //将指定的ANSI字符串的存放地址交给ESI寄存器
45362D55 PUSH EBX //恢复代码
45362D56 PUSH EBX //恢复代码
45362D57 PUSH EBP //恢复代码
45362D58 JMP HHA.4530FA66 //返回原程序
45362D5D NOP
修改后程序执行正常……不再出现“ERROR_INVALID_NAME”和“ERROR_PATH_NOT_FOUND”错误,但OLLYDBG加载调试时“hhw.exe”会出现异常,不去管她了……
三:相关提示:
HHW可从MS站点下载,好象该程序已不再更新了……
修改后的“hha.dll”文件可从我的Blog下载,将“hha.dll”与“hhw.exe”程序放在在同一目录下即可。
Blog:
http://timw.yeah.net
http://timw.126.com
祝大家新春快乐,万事如意!!!
16:16 2007-02-22
22:33 2007-02-23 修