Handler
Type 4
这类handler很简单, 在1字节编码opcode中只有1个,使用2字节OpcodeDetail数据,可以合并到Type 1里。之所以单独列出来是因为其功能比较特殊,用于执行非模仿指令。
![]()
只列出与功能相关的代码。
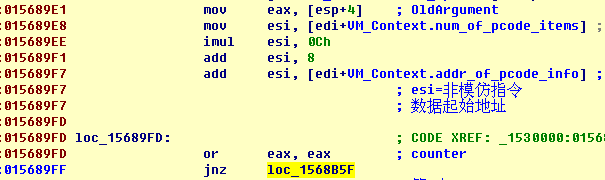

只使用Key1解码的OldArgument,由switch-case压入的NewArgument未用。
VM_Context.num_of_pcode_items为当前VM保护代码可以在VM内执行的代码块数。在Part1中已经提到过了,当存在VM不能模仿的代码时,这个值比PUSH/JMP下实际的数据项数小。
OldArgument是个index,指定应使用非模仿指令数据的第几项,以解析退出VM后的执行地址。上面的代码跳过PUSH/JMP下的“正常”数据,根据index值定位非模仿指令所属数据。
还是以Part1里那段CVDemo的代码来说明。
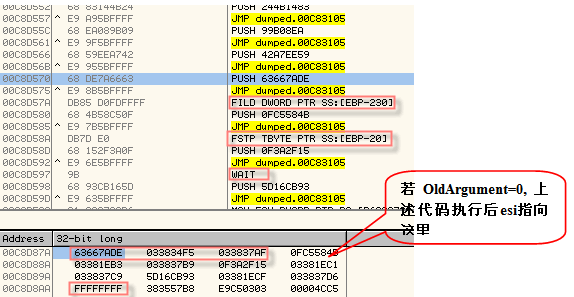
dump窗口红框内的数据对应最后1段“正常”的VM保护代码。在其后的3组数据对应3条非模仿指令。
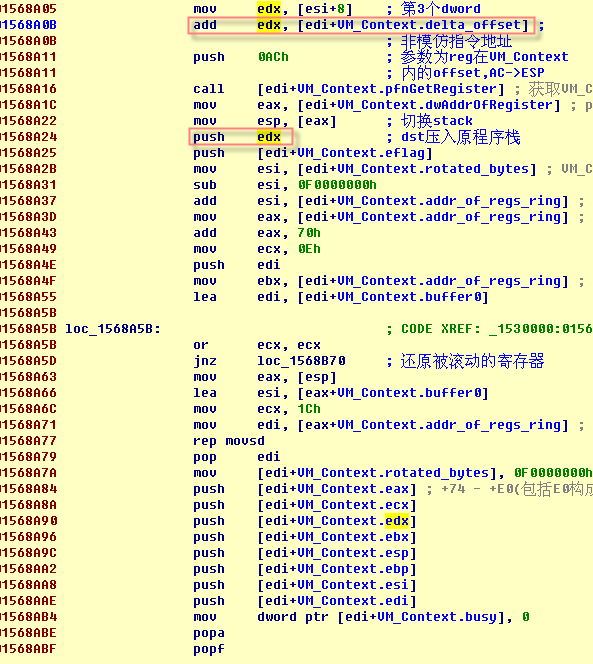
取数据项第3个dword,加DeltaOffset即非模仿指令地址。后面的就不多说了,恢复环境退出VM。
至此我们已经分析完了Themida VM所有handler类型。下面给出完整的VM指令集。2字节opcode全部是1字节opcode的复制品,重叠的handler其对应关系也可变。

1
字节opcode 08与2字节opcode 1F 00使用的是同1个handler,但换个程序与08对应的可能是另一个2字节opcode,即Themida VM的2字节opcode是个动态指令集。1字节opcode的含义及访问PCODE各field时使用的offset是固定的,当然作者完全可以把这个也搞成动态的J。下面只列出1字节opcode,功能以伪码说明(opcode的名字不一定合适J)。
Themida
VM Instruction Set_____________________________________________
| Opcode |
Type |
Mnemonics |
| 00 |
1 |
Vm_Push只支持32位操作 if((flag.ByRef) || (flag.OperateEsp)) { if(flag.FS) push
fs:[NewArgument] else
push [NewArgument] } else push NewArgument |
| 01 |
1 |
Vm_POPif(flag.EFlag) dst = VM_Context.Eflag ; 等价于popf else dst = NewArgument if(flag.FS) pop fs:[dst] ; (OperandSize = 8/16/32位) else pop [dst] ; (OperandSize = 8/16/32位) |
| 02 |
1 |
Vm_Mov 只支持32位操作 mov [NewArgument],OldArgument |
| 03 |
3 |
Vm_Jxx 这个难以用伪码描述;-) |
| 04 |
1 |
Vm_Push0在VM栈内压入0(32位) push 0 |
| 05 |
4 |
Vm_ExecuteNoEmulatedOpcodejmp NonEmulatedOpcode[OldArgument] |
| 06 |
1 |
Vm_IMUL32if(flag.Stack) { imul [esp+4],[esp] (OperandSize
= 16/32位) } |
| 07 |
1 |
Vm_ADCif(flag.Stack) { adc [esp+4],[esp] (OperandSize
= 8/16/32位) } else if(flag.ByRef) { VM_Context.register = adc([NewArgument],OldArgument)
; 32位 } |
| 08 |
1 |
Vm_ADDif(flag.Stack) { add [esp+4],[esp] (OperandSize
= 8/16/32位) } else if(flag.ByRef) { VM_Context.register = add([NewArgument],OldArgument)
; 32位 } |
| 09 |
1 |
Vm_ANDif(flag.Stack) { and [esp+4],[esp] (OperandSize
= 8/16/32位) } else if(flag.ByRef) { VM_Context.register = and([NewArgument],OldArgument)
; 32位 } |
| 0A |
1 |
Vm_CMPif(flag.Stack) { cmp [esp+4],[esp] (OperandSize
= 8/16/32位) } else if(flag.ByRef) { VM_Context.register =
cmp([NewArgument],OldArgument) ; 32位 这里显然有bug,可以看出这些代码是用同一个函数生成的,如 MakeOpcodeWithTwoOperandsJ } |
| 0B |
1 |
Vm_ORif(flag.Stack) { or [esp+4],[esp] (OperandSize
= 8/16/32位) } else if(flag.ByRef) { VM_Context.register =
or([NewArgument],OldArgument) ; 32位 } |
| 0C |
1 |
Vm_SUBif(flag.Stack) { sub [esp+4],[esp] (OperandSize
= 8/16/32位) } else if(flag.ByRef) { VM_Context.register =
sub([NewArgument],OldArgument) ; 32位 } |
| 0D |
1 |
Vm_TESTif(flag.Stack) { test [esp+4],[esp] (OperandSize
= 8/16/32位) } else if(flag.ByRef) { VM_Context.register =
test([NewArgument],OldArgument) ;32位 与Vm_CMP同样的bug } |
| 0E |
1 |
Vm_XORif(flag.Stack) { xor [esp+4],[esp] (OperandSize
= 8/16/32位) } else if(flag.ByRef) { VM_Context.register =
xor([NewArgument],OldArgument) ; 32位 } |
| 0F |
1 |
Vm_MOVZX8if(flag.Stack) { if(1 == OperandSize) ; 16<-8
movzx word ptr [esp+4],byte ptr [esp] else if(2 == OperandSize) ;
32<-8
movzx dword ptr [esp+4],byte ptr [esp] } |
| 10 |
1 |
Vm_MOVZX16if(flag.Stack) { if(1 == OperandSize) ; 16<-8
movzx word ptr [esp+4],byte ptr [esp] else if(2 == OperandSize) ;
32<-16
movzx dword ptr [esp+4],word ptr [esp] 与上面的区别在可处理16位值 } |
| 11 |
1 |
Vm_Push0在VM栈内压入0(32位) push 0(与04)重复 |
| 12 |
1 |
Vm_INCif(flag.Stack) { add [esp+4],1 ; 8/16/32位 } 执行前VM栈内有2个值,[esp]=1,[esp+4]为dst,handler内直接用硬编码值1,对应INC |
| 13 |
1 |
Vm_RCLif(flag.Stack) { rcl [esp+4],[esp] (OperandSize
= 8/16/32位) } else if(flag.ByRef) { VM_Context.register =
rcl([NewArgument],OldArgument) ; 32位 } |
| 14 |
1 |
Vm_RCRif(flag.Stack) { rcr [esp+4],[esp] (OperandSize
= 8/16/32位) } else if(flag.ByRef) { VM_Context.register =
rcr([NewArgument],OldArgument) ; 32位 } |
| 15 |
1 |
Vm_ROLif(flag.Stack) { rol [esp+4],[esp] (OperandSize
= 8/16/32位) } else if(flag.ByRef) { VM_Context.register =
rol([NewArgument],OldArgument) ; 32位 } |
| 16 |
1 |
Vm_RORif(flag.Stack) { ror [esp+4],[esp] (OperandSize
= 8/16/32位) } else if(flag.ByRef) { VM_Context.register =
ror([NewArgument],OldArgument) ; 32位 } |
| 17 |
1 |
Vm_SAL(实际代码用shl) if(flag.Stack) { sal [esp+4],[esp] (OperandSize
= 8/16/32位) } else if(flag.ByRef) { VM_Context.register =
sal([NewArgument],OldArgument) ; 32位 } |
| 18 |
1 |
Vm_SARif(flag.Stack) { sar [esp+4],[esp] (OperandSize
= 8/16/32位) } else if(flag.ByRef) { VM_Context.register = sar([NewArgument],OldArgument)
; 32位 } |
| 19 |
1 |
Vm_SHL(实际代码用shl实现,由于shl/shr = sal/sar,根据指令的前后关系,这里命名为shl) if(flag.Stack) { shl [esp+4],[esp] (OperandSize
= 8/16/32位) } else if(flag.ByRef) { VM_Context.register = shl([NewArgument],OldArgument)
; 32位 } |
| 1A |
1 |
Vm_SHRif(flag.Stack) { shr [esp+4],[esp] (OperandSize
= 8/16/32位) } else if(flag.ByRef) { VM_Context.register = shr([NewArgument],OldArgument)
; 32位 } |
| 1B |
1 |
Vm_DECif(flag.Stack) { sub [esp+4],1 ; 8/16/32位 } 执行前VM栈内有2个值,[esp]=1,[esp+4]为dst,handler内直接用硬编码值1 |
| 1C |
1 |
Vm_ExitVM这里看起来没做什么,取进入handler时的[esp]->eax,mov eax,eax,再用stosd送回vm栈.如果写解码程序会发现,这里解出的下1个pcode数据地址超出了当前pcode数据地址范围,2个opcode也超出取值范围.估计这代表pcode数据结束 |
| 1D |
1 |
Vm_MOVSX8if(flag.Stack) { if(1 == OperandSize)
movsx word ptr [esp+4],byte ptr [esp] else if(2 == OperandSize)
movsx dword ptr [esp+4],byte ptr [esp] } |
| 1E |
1 |
Vm_MOVSX16if(flag.Stack) { if(1 == OperandSize) ; 16<-8
movsx word ptr [esp+4],byte ptr [esp] else if(2 == OperandSize) ;
32<-16
movsx dword ptr [esp+4],word ptr [esp] } 与上面的区别在这里,可处理16位值 |
| 1F |
1 |
Vm_CLCclc |
| 20 |
1 |
Vm_CLDcld |
| 21 |
1 |
Vm_NOP
nop |
| 22 |
1 |
Vm_CMCcmc |
| 23 |
1 |
Vm_STCstc |
| 24 |
1 |
Vm_STDstd |
| 25 |
1 |
Vm_STIsti |
| 26 |
1 |
VM_SetEbpDeltaOffsetVM_Context.ebp
= VM_Context.delta_offset |
| 27 |
1 |
Vm_BTif(flag.Stack) { bt [esp+4],[esp] ; (OperandSize = 16/32位) } |
| 28 |
1 |
Vm_BTCif(flag.Stack) { btc [esp+4],[esp] ; (OperandSize = 16/32位) } |
| 29 |
1 |
Vm_BTRif(flag.Stack) { btr [esp+4],[esp] ; (OperandSize = 16/32位) } |
| 2A |
1 |
Vm_BTSif(flag.Stack) { bts [esp+4],[esp] ; (OperandSize = 16/32位) } |
| 2B |
1 |
Vm_SBBif(flag.Stack) { sbb [esp+4],[esp] (OperandSize
= 8/16/32位) } else if(flag.ByRef) { VM_Context.register = sbb([NewArgument],OldArgument)
; 32位 } |
| 2C |
1 |
Vm_MUL注意结果保存方式,[esp],[esp+4]都用了 if(flag.Stack) { mul [esp+4],[esp] (OperandSize
= 8/16/32位) } |
| 2D |
1 |
Vm_IMUL8注意结果保存方式,[esp],[esp+4]都用了 if(flag.Stack) { imul [esp+4],[esp] (OperandSize
= 8/16/32位) } 与opcode
06比较,前者不支持8位,只保存结果的低位部分 |
| 2E |
1 |
Vm_DIVif(flag.Stack) { div [esp+8]:[esp+4],[esp] (OperandSize
= 8/16/32位) } div为16b/8b,32b/16b,64b/32b,vm栈上实际有3个dword,按需要解释其size,注意计算结果的保存方式 |
| 2F |
1 |
Vm_IDIVif(flag.Stack) { idiv [esp+8]:[esp+4],[esp] (OperandSize
= 8/16/32位) } idiv为16b/8b,32b/16b,64b/32b,vm栈上实际有3个dword,按需要解释其size,注意计算结果的保存方式 |
| 30 |
1 |
Vm_BSWAPif(flag.Stack) { bswap [esp] ; (OperandSize
= 8/16/32位) } Bug?从Intel手册看,bswap只应对32位寄存器使用.Themida对8/32位操作用bswap
eax,对16位用bswap ax(用0x66前缀),可能有问题 |
| 31 |
1 |
Vm_NEGif(flag.Stack) { neg [esp] ; (OperandSize
= 8/16/32位) } |
| 32 |
1 |
Vm_NOTif(flag.Stack) { not [esp] ; (OperandSize
= 8/16/32位) } |
| 33 |
1 |
Vm_Push0在VM栈内压入0(32位) push 0 |
| 34 |
1 |
Vm_Push0在VM栈内压入0(32位) push 0 |
| 35 |
2 |
Vm_MovReg
|
| 36 |
2 |
Vm_AddReg |
| 37 |
2 |
Vm_SubReg |
| 38 |
2 |
Vm_OrReg |
| 39 |
2 |
Vm_XorReg |
| 3A |
2 |
Vm_AndReg |
| 3B |
2 |
Vm_CmpReg |
| 3C |
1 |
Vm_Loadmov VM_Context.register,NewArgument |
| 3D |
1 |
Vm_Push0在VM栈内压入0(32位) push 0 |