Themida的VM从v
前几次手工修复代码后,累得失去了写文章的兴趣,这次是文章先行。目前我写不出通用的解码程序,所以仅仅是篇文章。截图是调试时做的,有的图上的注释可能不够准确,没有再一一修改。细节太多,错误难免。另外,以前零零散散写过一些东西,难免会有炒冷饭的部分,见谅J。
下面的所有讨论都针对Themida v
Virtual
Machine入口代码
下面以Themida v
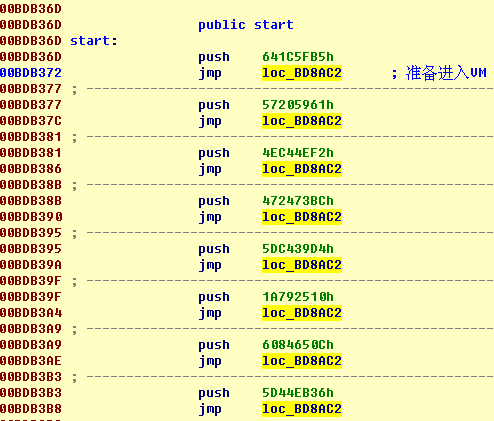
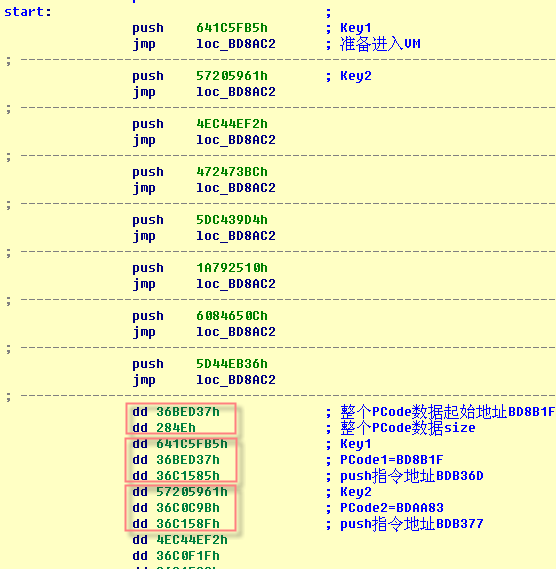
在Dump点的代码如图。连续的PUSH/JMP代码,JMP的目的地址相同。代码下面是这块被保护代码(stolen codes)对应 PCODE数据地址信息。
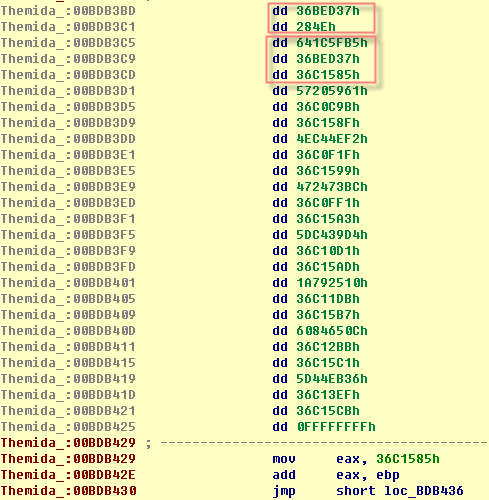
前2个DWORD有自己的含义。后面每3个DWORD为1组,对应上面的1个PUSH/JMP指令对,具体含义后面解释。以FFFFFFFFh结束。可以看到,PUSH的DWORD就是对应组内的第1个DWORD。
跟进loc_BD
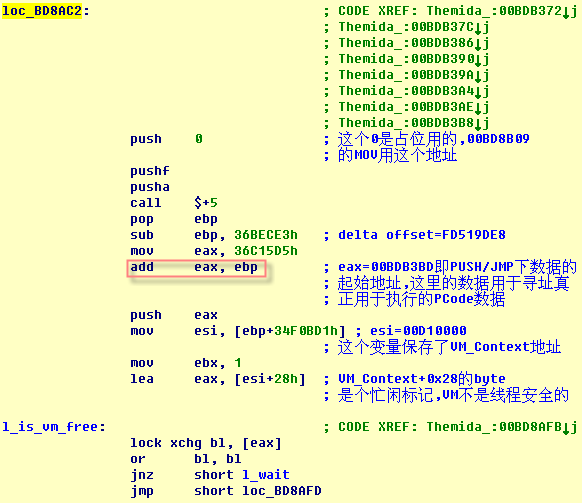

这部分代码是stolen codes专有的,每处用VM保护的代码都有自己的1份。在VM_Context内保存了2个值, PCODE数据表地址和这块代码内包含的PUSH/JMP指令对数。ret到公用的context保存代码。
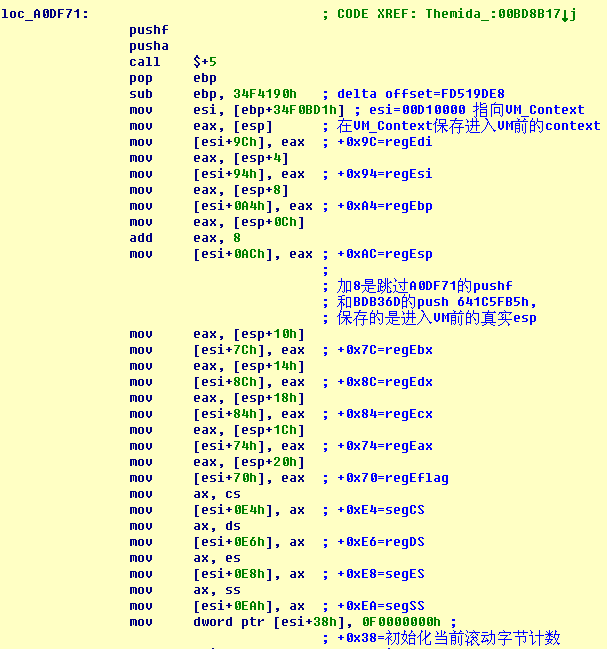
在VM_Context内保存进入VM前的环境。


现在再来看看Dump点的代码和数据。
首先,为什么会有多个PUSH/JMP? VM对代码的保护是“平面”的,如果被保护代码中包含有call,Themida不会将被调用函数的代码也纳入VM保护。执行到该处时,控制退出VM。执行完返回时,需要用PUSH/JMP重新进入VM。stolen codes对应的代码出现了8个PUSH/JMP指令对,意味着这段代码内存在7个call(第8次进入VM后,退出VM时控制返回到OEP处stolens codes结束后的代码地址)。
相应的,每次进入VM,需要指定对应的PCode数据(可以看作PCode的指令指针),即整个stolen codes对应的PCode数据也被分成8部分。PUSH/JMP中PUSH的值实际是个key,用来在下面的数据表中搜索对应的PCode地址。
把Delta Offset加到地址数据上可以看得更清楚。
上面数据组内的第3项代表了PUSH/JMP中PUSH指令的地址。实际上,前面的描述不够准确,这里不一定是PUSH Imm32。看看下面这段代码(来自Code Virtualizer Demo
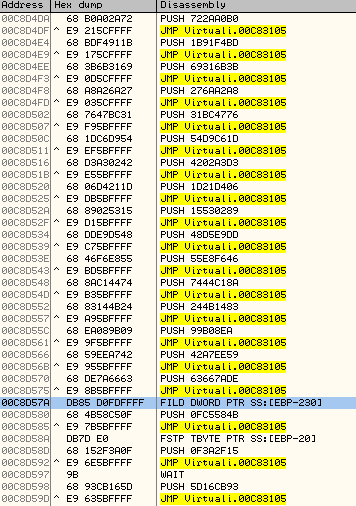
注意最后的3组。PUSH/JMP前出现了别的指令。
FILD DWORD PTR SS:[EBP-230]
FSTP TBYTE PTR SS:[EBP-20]
WAIT
这些是Themida VM不能模仿的指令。此时上述第3个dword指向非模仿指令的地址。VM_Context+0x
被保护代码中每出现1条VM不能模仿的指令,就会生成1组这样的指令。执行时退出VM,执行非模仿指令,再重新进入VM。不过这些细节暂时不必理会。后面会详细解释handler的类型与执行细节。
VM的内存结构_________________________________________________________
在较早的版本中,VM代码保存在多块内存中。大约从
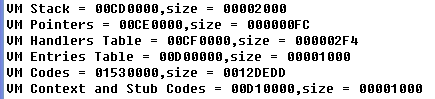
VM Stack
VM使用的8KB stack
VM 2-Bytes-Opcode Table1
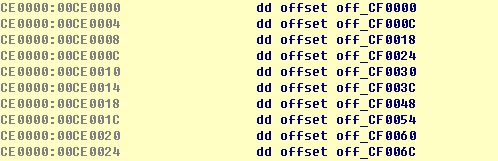
这是张地址表,指针地址是连续的(这里了和截图不同的名字)。
VM 2-Bytes-Opcode Table2
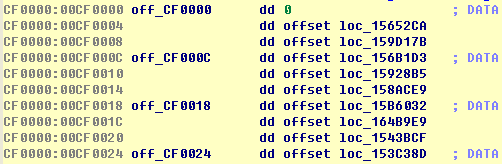
Handler地址表,每3个地址为1组,被上面表内某项所指。非0值代表1个handler地址,共158项。
VM 1-Byte-Opcode Table
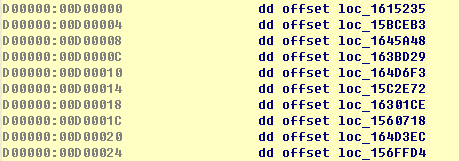
另1张Handler地址表,共62项。用PUSH/JMP进入 VM时,第1个handler地址是从这张表查的。反过来,158个Handler地址数据中,除去这62项外的其余Handler永远不会在VM入口使用。注意这张表内所有的handler地址,在上面包含158个非0值的表内都有。
进入VM时的查表代码。
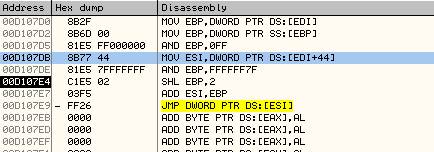
取PCode数据第1字节,其低7位用来查VM 1-Byte-Opcode Table。
VM Codes
虚拟机handler代码。
VM Context and Stub Codes
全局的VM_Context及上图的进入VM查表代码。
VM
OPCODE_______________________________________________________
为了理解opcode,先复习一下Intel指令格式。以下内容Copy自<The Art of Disassembly>。
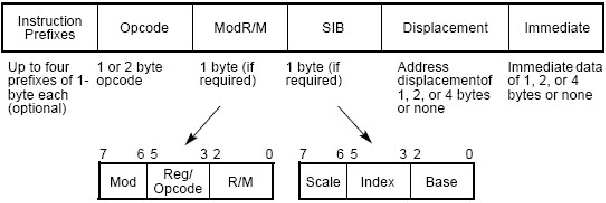
![文本框: We said that the processor has a decoding table, that means it requires a signature to be decoded. We can think about the [CODE] block as this signature,that tells the processor exactly what instruction to execute, and what kinds of rules should the instruction have.](ThemidaVM1.files/image031.gif)
唯一的非可选项为Opcode。
Opcode的本质是处理器用来查解码表的索引。通过查表,才能获知究竟要执行什么操作,需要什么操作数。实际的操作取决于处理器对查表结果的解释。再来看Thmida VM中出现的3张表。分两种情况。
进入VM时的查表动作,使用1-Byte-Opcode Table
取PCode数据第1字节的低7位,用作查1-Byte-Opcode表的索引。该索引值就是1字节的opcode编码。7位的可取值范围为0-127(当前该表有62项数据,即0-61)。当执行的VM指令为JMP/Jxx时,如果要执行跳转操作,也会使用1字节opcode,用前面提到的查表代码进入对应的handler。
在VM内连续执行PCode时,使用2-Bytes-Opcode
Table
在VM内连续执行时,会从PCode数据内解出2个字节值,用于定位执行下一条pcode指令的handler。Byte1用来查2-Bytes-Opcode Table1。假设为0,取第1项。

地址数据为CF0000。指向2-Bytes-Opcode Table2内某项。
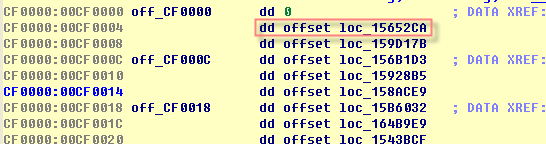
假设Byte2为1,定位到CF0000处3个dword的第2项,即handler地址。2个byte 实际就是2字节opcode编码(00 01)。
第1张表当前有63项,即opcode1取值为0-62。第2张表内的dword每3个为1组,只能为0-2,即opcode2取值为0-2。地址值为0的数据项可能代表保留的opcode编码。
注意,1字节opcode表内所有的handler地址,在2字节opcode表内都存在,即所有的1字节opcode都与某个2字节opcode重叠,指向相同的handler。看起来1字节opcode完全是多余的,为什么不只使用2字节opcode?
为了提高执行效率,Themida在每个handler内包含了分发代码, 从pcode数据内解码出下一条指令的opcode,查表得到对应的handler地址,以jmp esi跳过去继续执行。这样可避免用一个巨大的switch-case语句来判断opcode值。这种技巧称为Threaded Interpretation。
当前执行指令对应的pcode数据内包含有下一条指令的opcode(2 bytes)和pcode数据地址(1 byte)。
进入VM时,第1条指令的pcode数据内包含有下一条指令的2字节opcode数据。第1条指令自己的opcode为pcode+0字节的低7位(pcode数据的地址来自PUSH/JMP下的对应数据,由前面图中的准备代码保存到VM_Context+0处)。即这项pcode数据包含了2条指令的opcode信息。如果只用2字节编码,显然pcode数据将占用更多的空间。我的理解是使用1字节编码的目的是节省空间。
另外,1字节opcode实际上涵盖了VM的全部指令,所有的2字节opcode都与某个1字节opcode重叠。这个后面再讲。