我眼中的数据对齐
作者:溟初
在看雪论坛关于memcpy的帖子 (<memcpy应该怎样写,同时庆祝新版开张>http://bbs.pediy.com/showthread.php?s=&threadid=14128) 中谈及了数据对齐的话题,重新唤起了我对它的思考(以前一直都似懂非懂,逐渐淡忘了^_^),纯属个人见解,请批评指正!
相关附件下载。
一、什么是数据对齐?请看官方的解释:
Note that words need not be aligned at even-numbered addresses and doublewords need not be aligned at addresses evenly divisible by four. This allows maximum
flexibility in data structures (e.g., records containing mixed byte, word, and doubleword items) and efficiency in memory utilization. When used in a
configuration with a 32-bit bus, actual transfers of data between processor and memory take place in units of doublewords beginning at addresses evenly
divisible by four; however, the processor converts requests for misaligned words or doublewords into the appropriate sequences of requests acceptable to the
memory interface. Such misaligned data transfers reduce performance by requiring extra memory cycles. For maximum performance, data structures (including
stacks) should be designed in such a way that, whenever possible, word operands are aligned at even addresses and doubleword operands are aligned at
addresses evenly divisible by four.
数据对齐是指W O R D变量应该总是存放在2的倍数的地址处,而D W O R D变量应该总是存放在4的倍数的地址处,等等。
二、数据对齐随处理器和编译器的不同而不同,处理好数据对齐可以提高程序的时空效率(节省空间,提高效率),特别是在汇编程序中。
1、在处理器方面:
从486起EFLAGS寄存器的第18位(AC),CR0寄存器的第18位(AM)用于数据对齐检查,只有当AC=1,AM=1,处理器工作在保护模式或者虚拟86模式的Ring3时,才进行数据对齐检查,
若不对齐发中断0x11。windows系列没有设置AC(AC=0)位,所以无论数据对齐与否均不会发中断,总是可以存取到正确的数据,但是存取不对齐的数据要比对齐的慢,因为80386dx
之后处理器的地址线只接受4的倍数的地址(数据线为32位),如果提供的地址不是4的倍数,处理器会转化为若干个4的倍数的地址去存取,每次存取4个字节的数据。比如:
(1)Mov ax,word ptr[3],会先把dword ptr [0]提取出来,然后从dword ptr[4]提取出来,把所需数据组装后放到数据线,如下图。

(2)Mov eax,dword ptr[2],与上面一样的提取,只是组装的数据不同。
2、在编译器方面(以微软的ml、link为例):
(1)全局变量:
在.data,.data?,.const,.code中存放的数据都是紧挨在一起的,变量之间不会留有任何空隙,所以极易发生数据不对齐的现象,特别是定义数组,数据不对齐更会降低存取效
率。
VC编译器的全局变量使用COMM,(好像能自动align,谁知道COMM的具体细节请告知谢谢) .c文件全局变量反汇编后是这样的:
_DATA SEGMENT
COMM _x:BYTE
COMM _y:DWORD
_DATA ENDS
当然我们也可以在MASM中显示的使用COMM。
建议:根据变量的大小合理的安排它们之间的前后关系,使之对齐,必要时可使用align,even,org,$等强制执行对齐,特别是结构体变量和数组。
比如:
.code
test1 db ?
test2 dw ?
test3 db ?
改为:
test1 db ?
test3 db ?
test2 dw ?
(2)函数参数和局部变量:
函数参数和局部变量存放在堆栈中,以ebp(mov ebp,esp,其实是esp)为基准,自动进行偏移量的对齐(相对于ebp的偏移量),而恰好ebp的值都是4的倍数,所以这些变量都是自动
对齐的。
经测验,dq,dd, real8,real4以双字对齐,dw,df,dt,real10以字对齐,db以字节对齐。
我是根据下图测验的:

TestAlign proc
local pad:byte,test1:real4
ret
TestAlign endp
建议:在调用一个函数前,最好别使用PUSH AX等使ESP-2的指令,这会影响数据对齐。如这样调用:
push bx
call TestAlign
pop bx
就会使ESP是2的倍数而不是4的倍数,导致数据不对齐。
(3)结构体字段对齐(在移植程序时需要特别考虑,写网络程序好像也很重要):
WORD_COUNT struct
lpLetter db ?
dwCount dQ ?
WORD_COUNT ends
wordCount WORD_COUNT <>
这些字段在内存中是怎样布置的?这要根据编译器的设置即ml的Zp选项。
ML /Zp[n],其中n为1,2,4,8,16。
在vc中相应的设置为:
<1>:project->setting->c/c++标签->code generation分类->struct member alignment中。
其实就是在cl中设置Zp的值。
<2>:在程序中多次使用#paragram pack(n)语句,改变某部分结构体的对齐设置。
这些选项只能设置结构体字段的对齐情况(偏移量对齐),它(ml)不能保证结构体变量的对齐(地址是最大字段的倍数,wordCount存放在8的倍数的地址),vc好像可以自动把
结构体变量放在对齐的地方(爽),如果设置的对齐模数(n)小于最大字段的倍数,则以设置的模数为准,如设置为1,字段之间不会有任何空隙(实际上是压缩了结构体)。
上述结构体:
当设置为为8、16时(浪费7b):

当为4时(浪费3b):

设置为2哪?你可以自己画一下^_^
结构体变量的开始地址:全局变量之间是无间隙排列的,因此需要手工对齐(align),局部变量会自动对齐。
建议:根据字段类型的大小合理安排字段之间的前后关系,使字段无空隙对齐以减少浪费空间,使用align使全局结构体变量对齐在结构体最大字段类型大小倍数的地址处。
(4)指令对齐:
.code 中 align、even只是对指令对齐(请察看memcpy.asm使用指令对齐的情况),在局部变量之间插入align,even将不起作用,在指令之间使用它们可能会自动插入一些不可预
知的指令(为了达到对齐编译器可能会留一些空隙)。
官方的解释:
Due to instruction prefetching and queuing within the CPU, there is no requirement for instructions to be aligned on word or doubleword boundaries.
(However, a slight increase in speed results if the target addresses of control transfers are evenly divisible by four.)
(5)段的对齐类型:
在MASM中.code、.data、.data?、.const段属性对齐类型为dword(另外还有byte,word,para,pag对齐类型) (谁知道怎样改变.code等的对齐方式,请告知谢谢!),即这些段以4的倍
数地址开始定位,因此在这些段中不能使用alin 8,align 16,align 32等等。如果要使用别其它对齐类型,请使用segment自定义段。
(6)PE文件中的SectionAlignment、FileAlignment:
好像与本文无关,不要啥都往这里堆!!!.
三、尝试分析\VC98\CRT\SRC\PLATFORM \memcpy.asm(VC6.0安装盘上, vc7. 0在安装盘crt\src\intel\下,你也可以从网上找到)
参见C语言版:CRT\SRC\MEMMOVE.C
Memcpy.asm总的思想是:当不覆盖时从前往后拷贝,覆盖时从后往前拷贝。
1、覆盖的情况:dst>src && dst < src + len时,如下图:

比如:src地址为100,dst为106,拷贝12个字符。

不处理覆盖情况(从前往后拷):

处理覆盖的情况(从后往前拷):

2、memcpy.asm代码分析。
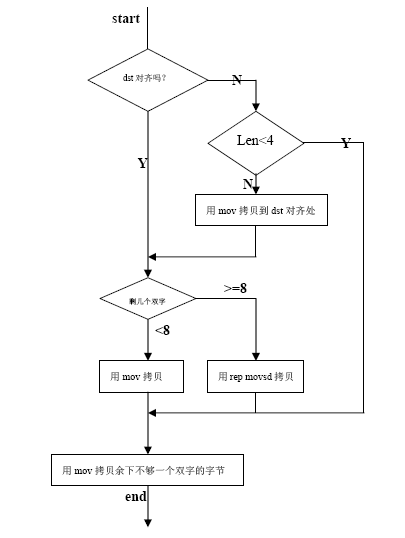
(1)对目标地址对齐拷贝,以提高效率。
(2)利用了处理器的流水线操作(U、V、N)。
(3)在指令中使用了align @WordSize,对指令对齐。
注:@WordSize:Two for a 16-bit segment or four for a 32-bit segment (numeric equate).
(4)当对齐后少于8个双字,使用mov指令,否则的话配合rep movsd,这里主要是考虑到时钟周期。
(5)试着画一下流程图。
从后拷和从前拷都是一样的流程
四、结束语:
这篇心得终于完成了,感觉自己的表达能力还是很有限,请批评指正,我的e_mail:hejiwen2001@sohu.com,如果它能给你带来帮助,我将很欣慰!,至少没有白忙活.
Reference:
1、《The art of assemle language》 来自http://asm.yeah.net/
2、《windows核心编程》 来自http://www.infoxa.com/
3、《INTEL 80386 PROGRAMMER'S REFERENCE MANUAL 1986 》 来自http://purec.binghua.com/
4、http://blog.dreambrook.com/soloist/archive/2004/12/12/388.aspx
5、http://wncj.vicp.net/course/hep/huibianyuyan/04-3.htm
6、http://msdn.microsoft.com/library
还有其他一些相关的网络资源,在此一一谢过。