先来道个歉,firfor,我当时发帖说“怕你这里有错。你再仔细看看代码,ebp+的是形参,ebp-的是局部变量。 ”其它的附加话都是无心说出来的,说话太过随意了,没想到让你产生了误解,先对你说声对不起。顺便自罚一下子。
先来道个歉,firfor,我当时发帖说“怕你这里有错。你再仔细看看代码,ebp+的是形参,ebp-的是局部变量。 ”其它的附加话都是无心说出来的,说话太过随意了,没想到让你产生了误解,先对你说声对不起。顺便自罚一下子。
以后坚持写读书笔记,这样理解快,自然掌握就快了。
C语言用char数据类型来表示一个8位ANSI字符,默认情况下,在源代码中声明一个字符串时,C编译器会把字符串中的字符转换成由8位char数据类型构成的一个数组:
char c = ‘A’;
char szBuffer[100] = “Hello world”;
Microsoft的C/C++编译器定义了一个内建的数据类型wchar_t,它表示一个16为的Unicode(UTF-16)字符。通过在字符串前加一个L来通知编译器该字符串应当编译为一个Unicode字符串。
wchar_t c = L’A’;
wchar_t szBuffer[100] = L”Hello world”;
微软又将这些定义为自己的数据类型,在WinNT.h中。
typedef char CHAR;//8-bit
typedef wchar_t WCHAR;//16-bit
//8-bit
typedef CHAR *PCHAR;
typedef CHAR *PSTR;
typedef CONST CHAR *PCSTR;
//16-bit
typedef WCHAR *PWCHAR;
typedef WCHAR *PWSTR;
typedef CONST WCHAR *PCWSTR;
还有下面的宏和类型,使用这些宏和类型,无论是ANSI还是Unicode字符,都能通过编译,而且使用Windows数据类型,有利于增强代码的可读性。
#ifdef UNICODE
typedef WCHAR TCHAR,*PTCHAR,PTSTR;
typedef CONST WCHAR *PCTSTR;
#define __TEXT(quote) L##quote
#else
typedef CHAR TCHAR,*PTCHAR,PTSTR;
typedef CONST CHAR *PCTSTR;
#define __TEXT(quote) quote
#endif
#define TEXT(quote) __TEXT(quote)
从Windows NT开始,Windows的所有版本都完全用Unicode来构建,也就是说,所有核心函数(创建窗口,显示文本,字符串处理等等)都需要Unicode字符串。调用Windows函数时,如果向它传入一个ANSI字符串(由单字节字符组成的一个字符串),那么函数首先会把字符串转换为Unicode,再把结果传给操作系统。如果希望函数返回ANSI字符串,那么操作系统会先把Unicode字符串转换为ANSI字符串,再把结果返回给我们的应用程序。所有这些转换都是在幕后进行的。执行这些字符串转换,系统会产生时间和内存上的开销。
C运行库的Unicode函数和ANSI函数(新的安全字符串函数):
在这些新函数发布以前,任何修改字符串的函数都会存在一个安全隐患:如果目标字符串缓冲区不够大,无法容纳生成的字符串,就会导致内存中的数据被破坏。
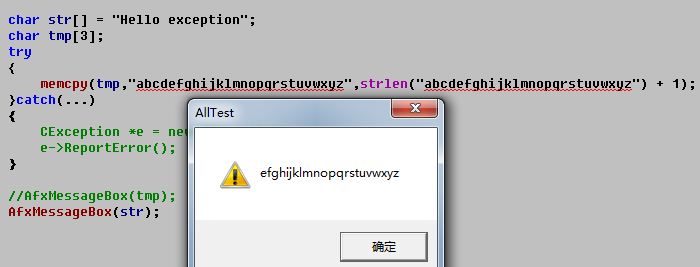
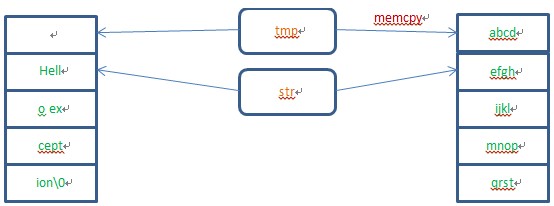
str在栈中的高地址,当memcpy的操作导致tem溢出的时候就会覆盖掉高地址处的内存。
于是这些新的安全函数便应运而生。现在每个函数(如_tcscpy或_tcscat)都有一个对应的新版本的函数。前面的名称相同,但最后添加了一个_s后缀,代表secure。所有这些新函数都有一个共同特征。在将一个可写的缓冲区作为参数传递时,必须同时提供它的大小。这个值应该是一个字符数,通过对缓冲区使用_countof宏,很容易计算这个值。
所有这些后缀为_s的安全函数的首要任务是验证传给它们的参数值。要检查的项目包括指针不为NULL,整数在有效范围内,枚举值是有效的,而且缓冲区足以容纳结果数据。如果这些检查中的任何一项失败,函数都会设置局部于线程的C运行时变量errno。然后,返回一个errno_t值来指出成功或失败。然而,这些函数并不实际返回。如果是一次调试版构建(debug),会显示一个Debug Assertion Failed对话框,然后终止应用程序。如果是发行版(release),则直接自动终止程序的运行。
C运行时实际上允许我们提供自己的函数,这样这些函数在检测到一个无效的参数时,就可以调用我们的函数。在这个函数中,我们可以进一步对异常进行处理。为了实现此功能我们必须定义好一个函数,原型如下:
void _invalid_parameter(
const wchar_t * expression,
const wchar_t * function,
const wchar_t * file,
unsigned int line,
uintptr_t pReserved
);
function,file,line,expression分别描述了出现了错误的函数名称,源代码文件,源代码行数,和代码中出现的错误描述。我们使用_set_invalid_parameter_handler来注册这个处理程序。我们还要在程序开头的地方调用_CrtSetReportMode(_CRT_ASSERT,0),禁用掉Debug Assertion Failed对话框,不然这个错误对话框依然会出现。这样我们就可以在程序中检查这个errno_t的返回值来判断函数执行是否成功。可能的返回值在errno.h中有定义。
下面看一个例子。
#include <stdio.h>
#include <stdlib.h>
#include <Windows.h>
#include <crtdbg.h>
#include <tchar.h>
#include <StrSafe.h>
void _invalid_parameter(
const wchar_t * expression,
const wchar_t * function,
const wchar_t * file,
unsigned int line,
uintptr_t pReserved)
{
_tprintf(_T("Invalid parameter detected in function %s.\n")
_T("File: %s Line: %d\n"), function, file, line);
_tprintf(_T("Expression: %s\n"), expression);
}
void _tmain()
{
_invalid_parameter_handler oldHandle;
TCHAR szStrFirst[5] = {_T('1'),_T('2'),_T('3'),_T('4'),'\0'};
_CrtSetReportMode(_CRT_ASSERT,0);
oldHandle = _set_invalid_parameter_handler(_invalid_parameter);
if (S_OK == _tcscpy_s(szStrFirst,_countof(szStrFirst),_T("01234")))
{
_tprintf("copy is ok!");
}
}

程序执行出错后的处理已经被我们的函数处理掉了。
C运行库还新增了一些函数,用于在执行字符串处理时提供更多控制。例如,我们可以控制填充符,或者指定如何进行截断。C运行库同时提供了函数的ANSI和Unicode版本。这些函数的名字如下:
StringCchCat,StringCchCatEx,StringCchCopy,StringCchCopyEx,StringCchPrintf,StringCchCopyEx,StringCchPrintf,StringCchPrintfEx。
可以看出,在所有方法的名称中,都含有一个“Cch”这表示Count of characters,即字符数:通常使用_countof宏来获取此值。另外还有一系列名称中含有“Cb”的函数,比如StringCbCat(Ex),StringCbCopy(Ex)和StringCbPrintf(Ex)。这些函数要求用字节数来指定大小,而不是字符数:通常使用sizeof操作符来获取此值。所有这些函数都返回一个HRESULT。
不同于安全(后缀为_s)的函数,当缓冲区太小的时候,这些函数会执行截断。为了判断是否发生这种情况,我们可以检测是否返回了STRSAFE_E_INSUFFICIENT_BUFFER。在这种情况下,源缓冲区可以装入目标可写缓冲区中的那一部分会被复制,而且最后一个可用的字符会被设为’\0’。所以,在前面的例子中,如果用StringCchCopy来替代_tcscpy_s,那么szStrFirst将包含字符串“0123”。注意,“截断”这个功能可能是也可能不是我们希望的,具体取决于我们想达到什么目标。使用这些函数的Ex版本,我们可以决定是否执行开销比较大的填充操作(尤其是目标缓冲区很大的时候),以及用什么字节值来作为填充符使用。
下面用个简单的例子来演示下。
代码如下:
#include<stdlib.h>
#include<tchar.h>
#include<strsafe.h>
int main()
{
TCHAR strBuffer[10] = _T("ABCDE");
TCHAR strBufferApp[20] = _T("ABCDE");
TCHAR strSource[] = _T("HELLO");
StringCchCat(strBuffer,_countof(strBuffer),strSource);
StringCchCatEx(strBufferApp,_countof(strBufferApp),strSource,NULL,NULL,
STRSAFE_FILL_BEHIND_NULL | STRSAFE_FILL_BYTE(0xFE));//函数运行成功后用0xfe填充剩余空间
return 1;
}
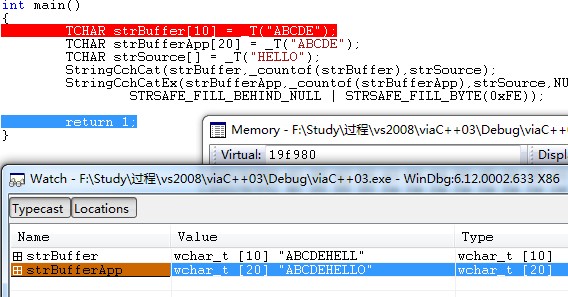
运行结果图。两个操作都完成了,下面看看内存处的情况。
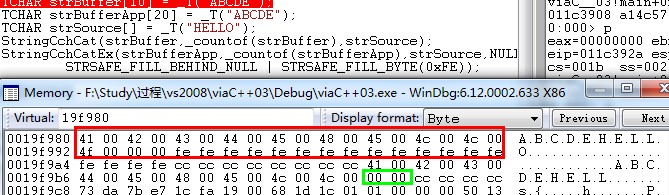
如图所示,strBufferApp在字符串连接完成后’\0’的后面都用0xfe来填充了,而strBuffer的结尾被设置了’\0’结束符,防止了缓冲区过小而导致的溢出问题。
Windows同样提供了各种字符串处理函数。其中许多函数(比如lstrcat和lstrcpy)已经不赞成使用了,因为它们无法检测缓冲区溢出问题。而在ShlwApi.h中定义了大量方便好用的字符串函数。
我们经常要比较字符串以进行相等性测试或者排序。为此,最理想的函数是CompareString(Ex)和CompareStringOrdinal。对于需要以符合用户语言习惯的方式向用户显示字符串,请用CompareString(Ex)进行比较。
int CompareString( LCID Locale,
DWORD dwCmpFlags,
LPCTSTR lpString1,
int cchCount1,
LPCTSTR lpString2,
int cchCount2
);
它的第一个参数指定了一个区域设置ID(locale ID,LCID),这是一个32位值,用来标识一种语言。函数使用这个LCID来比较两个字符串,具体的做法是检查字符在LCID所标识的语言中的含义。以符合当地语言习惯的方式来比较,得到的结果对最终用户来说更有意义。不过,这种比较比基于序数的比较(ordinal comparison)慢。我们可以调用Windows函数GetThreadLocale来得到主调线程的LCID。其余4个参数指定了两个字符串及其各自的字符长度(字符数,而不是字节数)。如果为cchCount1参数传入负数,函数会假设lpString1字符串是以0来结尾的,并计算字符串的长度;同样的道理适用于后两个参数。如果需要更高级的语言选项,那么应该考虑CompareStringEx函数。
为了比较程序内部所用的字符串(如路径名,注册表项/值,XML元素/属性等),应该使用CompareStringOrdinal。由于这个函数执行的是码位(code-point)比较,不考虑区域设置,所以速度很快。
它们的返回值有别于C运行库的*cmp字符串比较函数的返回值。0表明函数调用失败,1表明lpString1小于lpString2,2表明lpString1等于lpString2,3表明lpString1大于lpString2。
代码未经严格测试,开发环境vs2008。功能很简单,顺便练练sdk程序。