一、控制流整平的作用
学逆向的人都知道,if-else、while、for具有典型的跳转等结构,即使通过多层嵌套、拓展条件等方法,依然可以通过“切片技术”来判断。有了这些依据,就给程序分析带来很多便利。
正是这个原因,为了增加程序逆向的难度,我们得使得这些特征结构变得模糊,并且能让类似“切片技术”这样基于具体语义分析的方法失效,迫使逆向分析人员进行完整的抽象语义分析,斩断所谓的“捷径”。
控制流整平的策略是这样的,它把所有的典型控制流以及其衍生结构“统而为一”,各种控制流的区别只是语义方面的,增加了理解控制流转换关系的难度。
二、什么是控制流整平
控制流整平迷惑,是通过打破程序原有的控制流之间的嵌套和顺序关系,使得变换后的程序控制流扁平化的混淆方法,其基本思想是令程序中所有的基本块拥有共同的前驱和后继代码块。
如下图(本文代码思路皆使用C语言表示)
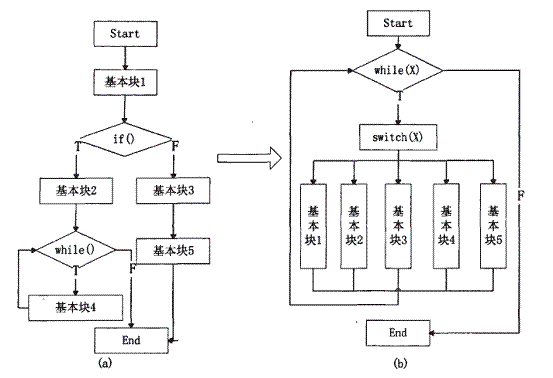
进行控制流整平后,使得面向过程的代码片段,原来比较清晰的控制流向混杂在一起,同时这也比较好的并行图形态,也有利于进一步的迷惑处理。
三、顺序流整平
对于单纯的顺序流,一般不用控制流平整的方法,我们有更好的处理方法,但这里为了从基础一步一步讲控制流平整,所以从最简单的顺序流开始。
举例:
int main()
{
int a,b,c;
Step1:
a=0;
Step2:
b=1;
Step3:
c=2
}
转换为:
int main()
{
int a,b,c;
int i=0
L1:
switch(i)
{
case 0:
a=0
i=1;
goto L1;
case 1:
b=1
i=2;
goto L1;
case 2
c=3;
i=3;
goto L1;
default:
NULL;
}
}
四、条件流平整
相信你看完顺序流平整的代码后,条件流平整应该也能“依葫芦画瓢”的写出来,唯一的问题就是条件控制流经常会有嵌套的问题,还有不同条件如何套在switch里。
例如:
int main()
{
int a,b;
bool b1=xxx,b2=xxx;
if(b1)
{
a=1;
if(b2)
b=1;
else
b=0;
}
转换为
int main()
{
int a,b;
bool b1=xxx,b2=xxx;
int i=b1
L1:
switch(i)
{
case true:
a=1;
i=b2+2;
goto L1;
case true+2:
b=1;
goto L1;
case false+2:
b=0;
goto L1
case false:
a=0;
goto L1;
}
}
五、循环控制流迷惑
循环控制流也可以被当做条件控制流一样转换,即循环和不循环的条件分支。但是为了取得更好的迷惑效果,单次循环内的顺序流也可以进行控制流整平,以增强迷惑效果。
六、分支变量保护
对于上面的方法面临的一个问题是:“分支变量值的如何保护?”。如果分支变量的值能够很容易地被分析出来,则程序可能被反迷惑成原程序,从而达不到代码迷惑的效果,下面提出几种可行的方案,供大家参考。
方法一:switch(i) 转换为 switch(f[i]),这样控制流向需要“即时计算”来确定,其实就是Hash。
方法二:演示代码中,各分支只进入一次,但可以使某些代码块多次重复进入,当然要考虑效率问题。
方法三:演示代码只有一层,如果多层嵌套,并且把同一层的代码块放入各层的不同深度,但其付出的空间和时间成本是一个值得注意的问题,并且其最大的缺点是后续添加其他迷惑技巧时可能受到限制。
方法四:方法三可以认为是纵向拓展,那么横向用多个switch之间的控制流连接,虽然它的复杂度比方法二小,但是继续添加迷惑技巧时受限较小。因为如果把方法一提到的“即时计算”部分挪到并行的switch里,这样前一个switch看起来都像正常的switch+break的形态。
- 标 题:二进制迷惑控制流整平
- 作 者:yangbostar
- 时 间:2011-02-24 12:27:35
- 链 接:http://bbs.pediy.com/showthread.php?t=129847