前一段时间写了两篇关于游戏封包格式反汇编的文章(虽然有一篇并没有分析出结果OTL),而且分析完了也没写出能提取资源的程序。于是这次我就由解包到翻译到封包到修改程序完整地写一篇教程。这次的游戏选择的是DC2PC,大小是7.62GB(- -|||)
一、资源分析
一般对于汉化游戏而言,脚本是汉化者最重要的部分(大多数时候还要提取出部分图片进行修改,部分有过场动画的游戏还要提取出动画嵌入字幕再封回去,至于声音的话……难道有人打算将日语的配音换成普通话么)。一般脚本文件要么是多个大小不超过1MB的文件放在特定的文件夹,要么就是单个大小不超过20M的单个文件,还有种情况就是多种资源封装在一起组成一个很大的资源文件。对于本例的游戏而言,脚本文件放在\DC2PC\Advdata\MES\目录下面,有很多个大小在20KB以内的文件。
至于图片等资源文件,为求简洁,这里就不分析了。
进入\DC2PC\Advdata\MES\下面,用WinHex随便打开一个文件,看到如下图所示:
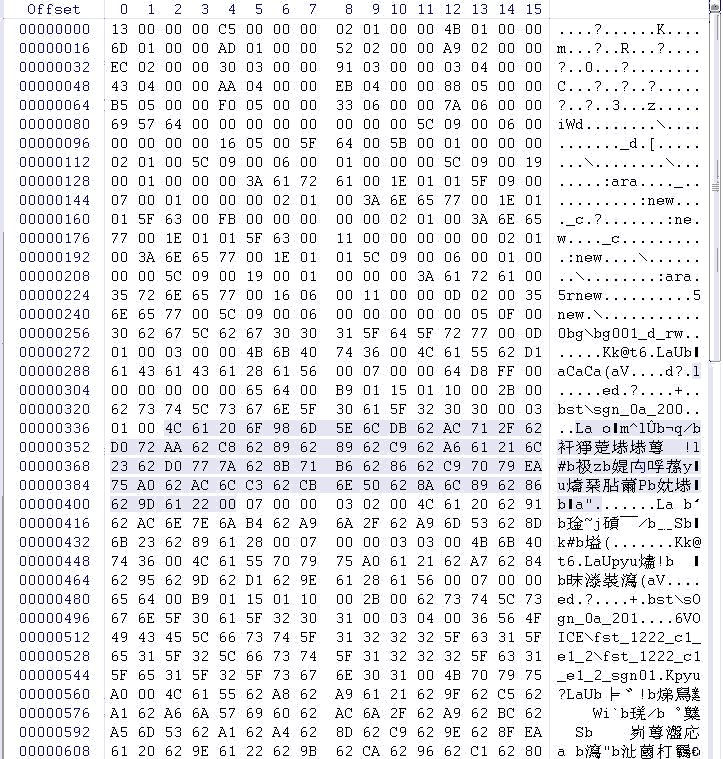
可以看出脚本文件里面能看到明文的要载入的资源位置,而后面有一段乱码,在日文编码中,一般日文的高位是0x80,可见,这段乱码是经过加密的。由此猜测,这段就是游戏中的对白。至于具体的加密方式……好吧,CIRCUS的游戏加密的方式一般都是每字节减0x20,这个也不例外。但本着学术研究的精神,为严谨起见,下面我还是会用OD进行调试的。
在这个文件夹发现有个start.mes的文件,打开看看发现没有像前面那样的乱码。如无意外,这个应该是控制游戏启动的脚本。既然这样,我们就应该在开始游戏的时候来进行分析了。
二、提取文本
到了这一步,就轮到od登场了,首先载入游戏,然后F9运行,然后在游戏界面点下开始游戏的用时在od的命令行输入bp CreateFileA,接着od就将打开文件的操作断了下来。一直按F9到打开的是mes后缀名的文件为止。而目前要打开的是fst_1216_a1_cmn.mes这个文件。接着对ReadFile下断,断下后单步运行到函数返回,回到下面的地方:
的地方:
接下来的一段代码是判断esi中的值进行不同的操作,而esi中的值是由[eax+AAD3B8]这个决定的,可以看出,程序是依靠脚本文件中每个字节的值来确定接下来要完成的操作。而当esi的值大于等于0x4A并且少于0x4E的时候,就会将接下来的乱码字符串复制到堆栈的临时变量区,然后进行解密。解密的代码如下:
#include<windows.h>
#include<iostream>
#include<string.h>
using namespace std;
int main()
{
HANDLE hfile=CreateFile
("c:\\fst_1216_a1_cmn.mes",GENERIC_READ,FILE_SHARE_READ,NULL,OPEN_EXISTING,FILE_ATTRIBUTE_ARCHIVE,NULL);
if(hfile==INVALID_HANDLE_VALUE)
{
cout<<"Can not open file!"<<endl;
return 0;
}
DWORD size=GetFileSize(hfile,NULL);
DWORD len;
char *buff=new char [size];
if(!ReadFile(hfile,(LPVOID)buff,size,&len,NULL))
{
cout<<"Can not read file!"<<endl;
CloseHandle(hfile);
return 0;
}
CloseHandle(hfile);
char temp[128]={0};
int j=0;
hfile=CreateFile("d:\\a1_cmn.txt",GENERIC_WRITE,FILE_SHARE_READ,NULL,OPEN_ALWAYS,FILE_ATTRIBUTE_ARCHIVE,NULL);
if(hfile==INVALID_HANDLE_VALUE)
{
cout<<"Can not create file!"<<endl;
return 0;
}
for(int i=0;i<size;i++)
{
j=0;
if(buff[i]==0x4c)
{
while(buff[i+j])buff[i+j++]+=0x20;
memcpy(temp,&buff[i],j);
i+=j;
temp[j]='\r';
temp[++j]='\n';
WriteFile(hfile,(LPVOID)temp,j,&len,NULL);
}
}
delete [] buff;
delete [] temp;
CloseHandle(hfile);
return 0;
}
提取出来的文本如下:

好吧,请无视掉翻译的质量问题,毕竟我们的重点是在程序的修改而不是翻译的问题,或者各位可以安慰自己说这几句其实是机器翻译的(当然这会极大地打击偶的自信心OTL)。
三、封包
幸好这个解密算法够简单,所以封包器就很好写(像我上两篇文章的那么复杂的加密算法,真不知道资源拆出来后要怎样封回去了,不过貌似那两个游戏不用封包也可以运行游戏……),封包器代码代码如下:
#include<windows.h>
#include<iostream>
#include<string.h>
using namespace std;
int main()
{
HANDLE hfile=CreateFile("c:\\fst_1216_a1_cmn.mes",GENERIC_READ,FILE_SHARE_READ,NULL,OPEN_EXISTING,FILE_ATTRIBUTE_ARCHIVE,NULL);
if(hfile==INVALID_HANDLE_VALUE)
{
cout<<"Can not open file!"<<endl;
return 0;
}
DWORD size=GetFileSize(hfile,NULL);
DWORD len;
BYTE *buff=new BYTE [size];
if(!ReadFile(hfile,(LPVOID)buff,size,&len,NULL))
{
cout<<"Can not read file!"<<endl;
CloseHandle(hfile);
return 0;
}
CloseHandle(hfile);
int j=0,nu=0;
hfile=CreateFile("d:\\a1_cmn.txt",GENERIC_READ,FILE_SHARE_READ,NULL,OPEN_ALWAYS,FILE_ATTRIBUTE_ARCHIVE,NULL);
if(hfile==INVALID_HANDLE_VALUE)
{
cout<<"Can not create file!"<<endl;
return 0;
}
DWORD textsize=GetFileSize(hfile,NULL);
BYTE *temp=new BYTE [textsize];
if(!ReadFile(hfile,(LPVOID)temp,textsize,&len,NULL))
{
cout<<"Can not read file!"<<endl;
CloseHandle(hfile);
return 0;
}
CloseHandle(hfile);
hfile=CreateFile("d:\\fst_1216_a1_cmn.mes",GENERIC_WRITE|GENERIC_READ,FILE_SHARE_READ,NULL,OPEN_ALWAYS,FILE_ATTRIBUTE_ARCHIVE,NULL);
if(hfile==INVALID_HANDLE_VALUE)
{
cout<<"Can not create new script file!"<<endl;
return 0;
}
for(int i=0;i<size;i++)
{
if(buff[i]>=0x4a&&buff[i]<0x4e)
{
while(buff[i++]){};
while(temp[j]!=0x0d)
{
temp[j]-=0x20;
WriteFile(hfile,(LPVOID)&temp[j++],1,&len,NULL);
}
WriteFile(hfile,(LPVOID)&nu,1,&len,NULL);
WriteFile(hfile,(LPVOID)&buff[i],1,&len,NULL);
j++;
}
else
{
WriteFile(hfile,(LPVOID)&buff[i],1,&len,NULL);
}
}
delete [] temp;
delete [] buff;
SetFilePointer(hfile,0,NULL,FILE_BEGIN);
size=GetFileSize(hfile,NULL);
buff=new BYTE [size];
if(!ReadFile(hfile,(LPVOID)buff,size,&len,NULL))
{
cout<<"Can not read file!"<<endl;
CloseHandle(hfile);
return 0;
}
DWORD *offsetarray=new DWORD [*(DWORD*)&buff[0]];
DWORD sizeofheader=(*(DWORD*)&buff[0])*4+4;
for(j=0,i=0;i<size;i++)
{
if(buff[i]>=0x4a&&buff[i]<0x4e)
{
offsetarray[j]=i-sizeofheader;
while(buff[i++]);
j++;
}
}
SetFilePointer(hfile,4,NULL,FILE_BEGIN);
WriteFile(hfile,(LPVOID)offsetarray,sizeofheader-4,&len,NULL);
delete [] offsetarray;
CloseHandle(hfile);
return 0;
}
四、程序修改
当我满心欢喜将新的脚本文件替换掉原来的文件之后,打开游戏,却出现了下面的画面:

干!
仔细想一下,由于原来的文本是用日文编码的,现在换成了GBK编码,不乱码就有鬼了,于是我们就要修正程序。
首先,用OD载入程序,右键选“查找当前模块中的所有名称”,看到有CreateFontA这个函数,查一下MSDN,发现这个函数的第
九个参数fdwCharSet正是决定字符编码的参数,在程序里面看一下,有几个连续的CreateFontA的调用:
还是没有显示出中文来!
现在该怎么办?这时应该看看程序利用哪些函数来进行输出的。用右键选“查看”-》“当前模块的所有参考”可以看到有个叫GetGlyphOutlineA的函数。在MSDN中有明确说明这个函数可以将字符转换成点阵来输出的。往上看,可以看到一段奇怪的代码:
 (关于编码边界检查的更详细内容可以参考这个链接http://bbs.sumisora.com/read.php?tid=211852)
(关于编码边界检查的更详细内容可以参考这个链接http://bbs.sumisora.com/read.php?tid=211852)就这样,这个游戏的汉化算是大功告成- -
PS.为什么只能算是大功告成,因为我写的封包器似乎有点问题,程序的修改方面也出现一些问题(到后面几句翻译的对白会出现错别字- -|||)最重要的一点是,整个游戏的文本有这么多,我就翻了开头的几句,这怎么能算是汉化完成啊
PS的PS.经某大牛指点,mes文件第一个双字是脚本里面文本的个数,接下来的一个数组是文本的偏移位置。虽然据我观察程序并不对这段进行读取……现在将封包程序改一下。另外在调用GetGlyphOutlineA前有两次边界检查,如无意外,第一次应该也要改的orz