内容:
- 标 题:破解vmp程序的关键点
- 作 者:海风月影
- 时 间:2009-02-23 09:23
- 链 接:http://bbs.pediy.com/showthread.php?t=82618
内容:
无花风月,我来推波助澜
PART I
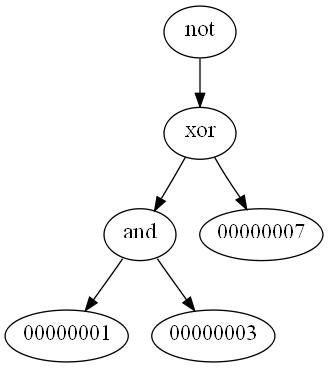
xor用真值表可以直接证明,另外还有一种非常好记的方法
L = ~(A&B) = A和B不都为1的位
R = ~(A|B) = A和B不都为0的位
L & R = A和B不都为1且不都为0的位 = 不同为1相同为0 = XOR
至于~等于或非/NOR自身
PDF 文件:
http://u4.ksu.edu.tw/gallery/458/98_01.pdf
NAND ' NOR 称为万用逻辑闸
因为我们可以单纯使用NAND或NOR来组成基本逻辑闸
因此NAND与NOR可以实现所有的布林函数

BINARY GAMES
~(~A+B)=~(~A+1-1+B)=~(-A-1+B)=~((B-A)-1)=A-B
这难道是...
A B A-B ~A+B 0 0 (0)0 (0)1 0 1 (1)1 (1)0 1 0 (0)1 (0)0 1 1 (0)1 (0)0
a test done some time ago
VMP没那么复杂
只是单纯用NOR这个万用闸去实现NOT'AND'OR'XOR
致于加法, VMP内部自有这种东西
add(d,d) ELF,Result
pushw(addb(wb,wb)) pushd(ELF)
add(w,w) EFL,Result
LZ的PART1的 a'&b' 等效于 (a+b)' 就是 NOR 闸
跟jcc较无关, 因为这是VMP的基, 很常用.
PARTIII的jmp指令, 就是改 ESI 而己, 跟上面混在一起了
vm.jmp(d+#d) ;ESI=[EBP]+[EBP+4]
PART IV的跳不跳观念跟我们平常不太一样.
由上面的#d决定. 通常 d=Target, #d=0 为跳 jmp(d+#d)
若 #d=-d 继续
--- 帖子无法编辑, 也看不到
接上楼, VMP内部也有 shl(d,w) EFL,Result 及 FS:[d0]:= d1
一些较为有目的性的指令
还原成可视(或称类asm)个人认为并没想像中的难.
一直看不到帖子, 只好再自言自语了, 希望版主弄成连续一点
为何说没想像中的那么难呢?
下列是很常见的一连3个VM指令
原 VM.ESP:
12FFB0 00000286
12FFB4 0012FFB8
1.经过 VM.push_esp , 变成:
12FFAC 0012FFB0
12FFB0 00000286
12FFB4 0012FFB8
2.再经过 VM.pushd([d]) , 变成:
12FFAC 00000286 <- 复制一份了
12FFB0 00000286
12FFB4 0012FFB8
3.再经过 VM.nor(d,d) EFL,Result 变成: 注: nor is NOR 闸
12FFAC 00000282 <- ELF
12FFB0 FFFFFD79 <- Result
12FFB4 0012FFB8
这3个步骤其实就是 NOT 0286h = FFFFFD79
紧接着上列3个步骤后, 常见下列的动作:
4. VM.pop 丢掉ELF, 变成:
12FFB0 FFFFFD79 <- Result
12FFB4 0012FFB8
5. pushd(decode(followWord)) <- 从opcode处取2 byte当数据, 符号扩展PUSHD
12FFAC FFFFF7EA <- 数据 (亦即 0815的not)
12FFB0 FFFFFD79 <- Result
12FFB4 0012FFB8
6. VM.nor(d,d) EFL,Result 变成:
12FFAC 00000202 <- ELF
12FFB0 00000004 <- Result
12FFB4 0012FFB8
7. VM.pop 丢掉ELF, 变成:
12FFB0 00000004 <- Result
12FFB4 0012FFB8
1~7 其实实现的就是 00000286 & 00000815 = 00000004
VMP是很正规的.
原先是在这版某讨论帖写的. 之前这版块管制.
稍稍整理独立出来. 己看过的就飘过吧.
讲一下 VMP, 及还原代码的可行性.
VMP其实不复杂, 反而是他的太单纯导致复杂化
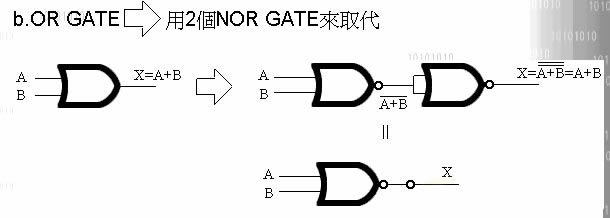
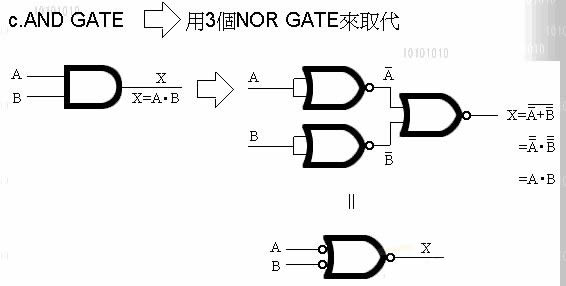
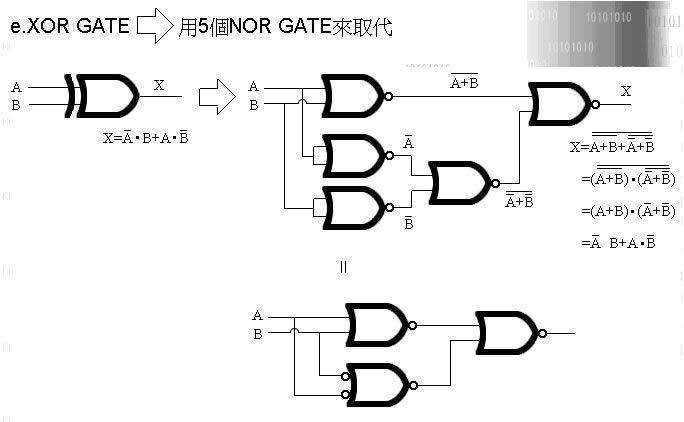
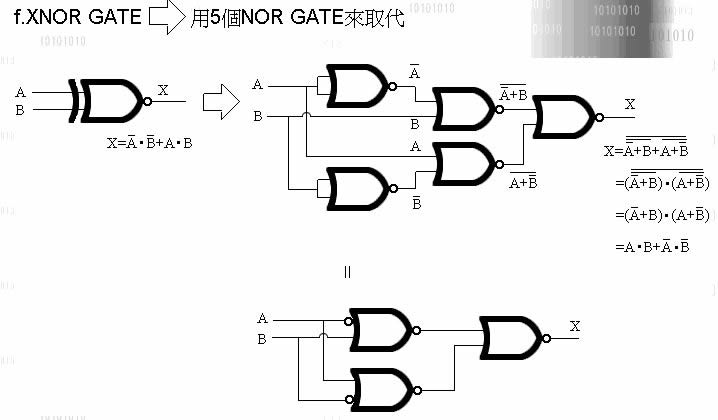
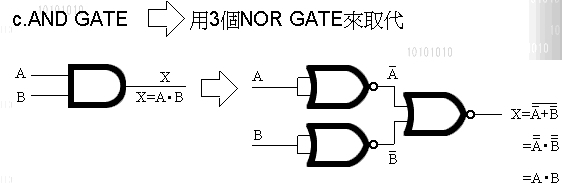
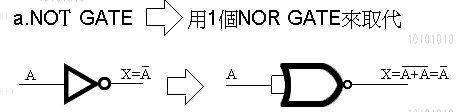
万用闸有二种, 一种叫 NOR Gate, 一种叫 NAND Gate.
即称万用, 就表示单靠他自己, 就能变换出 OR ' NOT ' AND ' XOR
VMP在VM内的运算选择了 NOR Gate 去实现 NOT'AND'OR'XOR
(实现图我列在最后)
致于加法, VMP内部自有这种指令(直接用 intel ADD 指令)
add(w,w) EFL,Result
add(d,d) ELF,Result
addb(wb,wb) ELF,Result
VMP内部也有 shl(d,w) EFL,Result 及 FS:[d0]:= d1
等等一些较为有目的性的指令.
所以还原成可视(或称类asm)个人认为并没想像中的难.
-----------------------------------------------------------------------------
VM 的条件跳转
条件跳转跟我们平常的观念不太一样.
这是 jmp : #delta=0
vm.jmp(d+#delta) ;ESI=[EBP]+[EBP+4]
上面的#delta的值将决定所谓的跳或不跳.
通常 d=Target, #delta=0 为跳 jmp(d+#d)
若 #delta=-d 则 ESI 的值不会变, 也就是不跳(继续执行)的意思了.
-----------------------------------------------------------------------------
为何说没想像中的那么难呢?
下列是很常见的一连3个VM指令
原 VM.ESP: *** 注: VM.ESP 是由 EBP 所表示 ***
12FFB0 00000286
12FFB4 0012FFB8
1.经过 VM.push_esp , 变成:
12FFAC 0012FFB0
12FFB0 00000286
12FFB4 0012FFB8
2.再经过 VM.pushd([d]) , 变成:
12FFAC 00000286 <- 复制一份了
12FFB0 00000286
12FFB4 0012FFB8
3.再经过 VM.nor(d,d) EFL,Result 变成: 注: nor is NOR 闸
12FFAC 00000282 <- ELF
12FFB0 FFFFFD79 <- Result
12FFB4 0012FFB8
这3个步骤其实就是 NOT 0286h = FFFFFD79
紧接着上列3个步骤后, 常见下列的动作:
4. VM.pop 丢掉ELF, 变成:
12FFB0 FFFFFD79 <- Result
12FFB4 0012FFB8
5. pushd(decode(followWord)) <- 从opcode处取2 byte当数据, 符号扩展PUSHD
12FFAC FFFFF7EA <- 数据 (亦即 0815的not)
12FFB0 FFFFFD79 <- Result
12FFB4 0012FFB8
6. VM.nor(d,d) EFL,Result 变成:
12FFAC 00000202 <- ELF
12FFB0 00000004 <- Result
12FFB4 0012FFB8
7. VM.pop 丢掉ELF, 变成:
12FFB0 00000004 <- Result
12FFB4 0012FFB8
1~7 其实实现的就是 00000286 & 00000815 = 00000004
(00000815被以NOT的型式硬编在OPCode)

所以 VMP 的 VM 是很正规的.
一个简单的80x86指令 : and reg, 00000815h
被分解成 (假设reg的值已入Stack)
VM.push_esp
VM.pushd([d])
VM.nor(d,d)
VM.pop
VM.pushd(decode(followWord))
VM.nor(d,d)
VM.pop
因为都是通过 VM.Execute 在分派的, 过于勇往直前的人就感觉 VM 一直在绕圈圈
-----------------------------------------------------------------------------
可以写个分析引擎, 全在 VM.Execute 这点分析
根据VM.Stack内容及ESI的变化, 应该可分析出90% 的接口入点 及 功能
(有些接口到底是什么功能得用套的)
当然了, 前提是 VM 有那些接口功能要知道
这可以算是我第一次看VMP, 现在的火热觉得不分析一下好像跟不上流行
我只看了半天就分析出大多数常用的接口功能
可见人眼对这种花指令'垃圾代码的适应性很强
从 EP 到 MessageBox('debugger has been found'), 下列是绰绰有余了(用不到那么多)
可见得大多功能的实现都只依赖固定几种在组合变化而己(配合上面我写的NOR闸的变化)
popd
pushd
push_esp
pushw(decode(flwb))
pushw(decode(flww))
pushd(decode(flwb))
pushd(decode(flww))
pushd(decode(flwd))
pushw(b[vm.decode(flwb)])
nor(d,d) EFL,Result
nor(bw,bw) ELF,wResult
add(d,d) ELF,Result
shr(d,bw) EFL,Result
shl(d,w) EFL,Result
add(d,d) ELF,Result
addb(wb,wb) ELF,wResult
pushw(b[d])
pushw(b(SS:[d]))
vm.decode(flwb):=bw
pushd([d])
SetFlag(d)
pushw(w(SS:[d]))
pushw(nor(w,w)) EFL,Result
add(w,w) EFL,Result
[vm.decode(followByte)]:= w
d:=[d]
[d0]:=d1
pushd(FS:[d])
FS:[d0]:= d1
SS:[d0]:= d1
SS:[d]
NewVM
VM.jmp(d0 + #d1)
VM.Exit
注 :
flwb : follow Byte
flww : follow Word
flwd : follow DWord
至于popd及pushd到底是作用于VM.Context的那一个, 我写了个脚本可跑出来(AL在决定的)
所以可正确翻译 push xx , push xx
所以应该大部份都可翻译出来.
例如之前那 7 条 VM 指令, 可直接翻成 and xxx, 00000815(硬编)
至于 xxx 到底是 EAX 或 ECX 或 内存... 得再往前看了.
就到这而. 己有利日后我遇到VMP该做什么事 ' 该做什么的逆向.
至于实现的编程不是我的强项了. 事实上是个弱鸡.
有问题不要问我, 因为我才刚接触.
阿门