第四部分:指令(Opcode)
Opcode是机器码中用来编码操作的部分,一条指令应该执行什么样的操作由这部分决定。Opcode的识别方式决定了整个反汇编引擎的框架,在学习完后面编码操作对象(ModR/M,SIB,Immediate)之后,大家就会发现,如何识别Opcode及其一些附加信息成了从代码上完成一个反汇编引擎的关键问题,事实上,不同的反汇编引擎的主要差别就在Opcode的识别方式。这部分本来该在后面讨论更个反汇编引擎的框架的时候详细讨论,但是这里还是先讲讲我对这部分的一些理解和实际经验。
4.1 指令Opcode与机器码的对应关系
我想如果大家没有研究过反汇编引擎之前,一定跟我一样对汇编或反汇编过程有一个这样的直观的误解:一种mnemonic操作对应于一定的机器码,反编译只要识别了机器编码,从mnemonic操作-机器码对应的表中查到到对应的mnemonic就能完成反汇编操作了。实际上,intel的复杂指令真的是名副其实地复杂,可能是现有所有cpu中最为复杂的。mnemonic与机器码的一一对应关系并不存在,甚至(从某种意义上来说),反过来这种关系也并不成立。但是,有一种一一对应的关系是一定存在的,那就是一定的操作对应于一定的机器码。
上面讲的那些对应关系可能把大家弄糊涂了,但都只是些概念上的东西,或者说直观上的一些东西,再加上大家对上面mnemonic、opcode机器码,等代表的涵义各有各的理解,我可能更无法表达我想说的意思了。还是用例子来说明吧:
1. 助记符与机器码之间没有一一对应的关系:
我想这个很好理解,翻看intel指令集说明,以Add为例子:
Mnemonic Opcode Instruction Discription
----------------------------------------------------------------------------
ADD 04 ib AL,imm8 Add imm8 to AL
ADD 05 iw AX,imm16 Add imm16 to AX
ADD 05 id EAX,imm32 Add imm32 to EAX
ADD 80 /0 ib r/m8,imm8 Add imm8 to r/m8
ADD 81 /0 iw r/m16,imm16 Add imm16 to r/m16
ADD 81 /0 id r/m32,imm32 Add imm32 to r/m32
ADD 83 /0 ib r/m16,imm8 Add sign-extended imm8 to r/m16
ADD 83 /0 ib r/m32,imm8 Add sign-extended imm8 to r/m32
ADD 00 /r r/m8,r8 Add r8 to r/m8
ADD 01 /r r/m16,r16 Add r16 to r/m16
ADD 01 /r r/m32,r32 Add r32 to r/m32
ADD 02 /r r8,r/m8 Add r/m8 to r8
ADD 03 /r r16,r/m16 Add r/m16 to r16
ADD 03 /r r32,r/m32 Add r/m32 to r32
可以看到,当add指令的操作对象不同的时候,指令编码是不同的。从机器码(Opcode)翻译到mnemonic的过程还直观一些,从Instruction翻译到机器码(Opcode)的汇编过程就没有那么容易了,尤其当存在后面将介绍的d位(影响两个操作码的顺序),翻译的过程将有更多的选择,如何选择最短的指令编码将是汇编程序要解决的最终要的问题。以Add举个例子吧:
d位的影响:
00401000 03C3 add eax, ebx
00401002 01D8 add eax, ebx
长短不一的指令编码:
00401007 03041B add eax, dword ptr [ebx+ebx]
0040100A 03045D 00000000 add eax, dword ptr [ebx*2]
尤其是后面的例子,当一个汇编新手用add eax, dword ptr[ebx*2]指令的时候,好的汇编器必需能够把其翻译成等价的上面的编码方式。指令越短,占用空间越少,cpu取码时间、译码时间越短,执行效率越高。
2. 机器码于助记符之间没有一一对应的关系。
这样说严格上将是不正确的,上面我说的是从某种意义上来说。现在我们看看到底我想说些什么。首先,看看intel官方手册中关于指令格式部分出现了Opcode的地方:

大家可以看到,除了1-3byte的正规Opcode编码,还有一个位置出现了Opcode,那就是ModR/M的子项的第二项。ModR/M的3-5bit的3个bit的名称(或涵义)是:Reg/Opcode,反斜杠“/”代表或者的意思,也就是3个bit可能用来编码一个寄存器操作对象,但同时也可能联合前面的Opcode一起编码指令。我上面提到的“从某种意义上来说”就是指的如果不考虑这里的Opcode,说实话这3个bit破坏了指令编码的和谐一致性。如果没有这3个bit,所有的Opcode只用前面的1-3个byte编码,识别过程将简化很多。intel为了缩短指令所占有的空间,为了提高指令编码的bit利用率,真是无所不用其极。大家也可能想得到,出现这3个bit的地方有两种情况:(a)指令的操作对象中没有寄存器,只有内存和立即数。如:F6 (000) Test r/m8 imm8(b)指令操作的对象中的寄存器是默认已知的。如:F6 (100) mul r/m8。下面给出整个Opcode为F6的指令:
Opcode Reg/Opcode Instruction
-----------------------------------------------
F6 1 TEST r/m8 imm8
F6 2 NOT r/m8
F6 3 NEG r/m8
F6 4 MUL r/m8
F6 5 IMUL r/m8
F6 6 DIV r/m8
F6 7 IDIV r/m8
“从某种意义上来说”也可以说成“从解码的代码实现的角度来说“,一般的情况是,我们读到了对应的Opcode,但是要确定其对应的操作,还需要接着再读取ModR/M中的Opcode部分,两个部分结合起来才能得到正确的指令编码。
4.2 Intel指令编码Opcode的几种类型。
在学习sivn等前辈的教程的时候,intel指令的编码方式中的“规则”,让我如何设计一张menmonic于编码对应的表的时候困惑了很久,说实话,直到现在我也没有能想到一种比较好的方法设计出一张既能利用这些“有趣”的规则,又能有者统一规则的翻译表出来。(最后,我选择了最直观,当然也是最土最愚蠢的方法:switch..case。原因是多方面的,其中最重要的原因就是,如果我还继续考虑如何设计一张优美的翻译表,我可能永远也没有办法实现一个反汇编引擎了,边学习,边考虑,以后再设计一张翻译表可能对我来说更现实。另外:switch..case能非常有效地利用这些“规则”,虽说swtich..case方法土,但是执行效率可能是最高的,而且忠实地实现了那句话“反汇编是解析出来的,而不是查表查出来的”)。下面我介绍一下我学习到的这些有趣的指令编码“规则”,或许朋友们在以后设计翻译表的时候可以再返回这里,当考虑一下这些“规则”:
1. Opcode中编码操作对象:
Opcode并没有那么单纯,intel的工程师们为了提高bit利用率,在一些指令Opcode部分编码了一些寄存器操作对象。大家可能也知道Intel的cpu通用寄存器就只有8个,编码这8个寄存器用3个bit就够了,甚至一些1byte的指令也能节省出这3个bit出来。
首先介绍一下intel对通用寄存器的编码,这个可能在后面会再重新介绍:
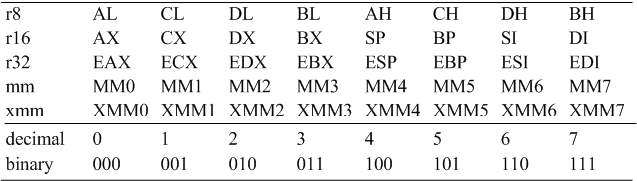
可以看到,intel对8位,16位,32位的寄存器采用相同的编码,前面在介绍一些指令前缀的时候已经介绍了Intel如何识别8位,16位和32位操作对象的,这里对寄存器的识别也用的是同样的方式。还有mm和xmm寄存器,这些寄存器用在mmx指令之中,解析mmx指令的时候,对应的寄存器要作相应的转换。
下面看看这些指令:(inc)
00401000 40 0100 0[000] inc eax
00401001 41 0100 0[001] inc ecx
00401002 42 0100 0[010] inc edx
00401003 43 0100 0[011] inc ebx
00401004 44 0100 0[100] inc esp
00401005 45 0100 0[101] inc ebp
00401006 46 0100 0[110] inc esi
00401007 47 0100 0[111] inc edi
我把方括号加上之后大家可能一眼就能看出来了,这些Opcode的区别就在于最后的3个bit不同,而且这3个bit代表的数字刚好对应着指令唯一的寄存器操作对象的编码。相似的指令还有dec r16/32(48-4F),push r16/32(50-57),pop r16/32(58-5F),xchg r16/32(90-97),mov r8, imm8(B0-B7),mov r16/32, imm16/32(B8-BF),bswp r16/32(0F C8- 0F CF)。(建议大家亲手在od中做一下实验,不麻烦,但能加深一些理解)
2. flag条件相关的指令编码格式:
先看看下面的这两组指令:(jcc related8)
00401000 > - 70 FE jo short 00401000 0111 [000]0
00401002 - 72 FE jb short 00401002 0111 [001]0
00401004 - 74 FE je short 00401004 0111 [010]0
00401006 - 76 FE jbe short 00401006 0111 [011]0
00401008 - 78 FE js short 00401008 0111 [100]0
0040100A 7A FE jpe short 0040100A 0111 [101]0
0040100C - 7C FE jl short 0040100C 0111 [110]0
0040100E - 7E FE jle short 0040100E 0111 [111]0
00401011 - 71 FE jno short 00401011 0111 [000]1
00401013 - 73 FE jnb short 00401013 0111 [001]1
00401015 - 75 FE jnz short 00401015 0111 [010]1
00401017 - 77 FE ja short 00401017 0111 [011]1
00401019 - 79 FE jns short 00401019 0111 [100]1
0040101B 7B FE jpo short 0040101B 0111 [101]1
0040101D - 7D FE jge short 0040101D 0111 [110]1
0040101F - 7F FE jg short 0040101F 0111 [111]1
上面一组指令和下面一组指令为互补指令,互补指令的差别很容易看出来,最后一个bit为1(set)则表示not。同组指令之间的差别在1-3bit这3个bit。
这些条件跳转指令根flag寄存器中的各个位密切相关。这些跳转指令的条件:
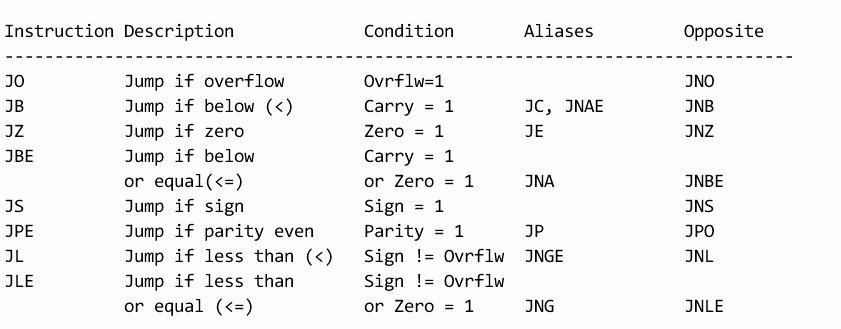
(PS:记得当初在svin的教程上看到过对这些条件跳转编码的一些解析,大致就是上面方括号内的不同位对应着标志寄存器中的不同的位,现在我找不到那部分了,而我自己又实在推算不出来。也罢,把资料呈上,有兴趣的可以看看,如果谁推算出来了或读到了svin教程中对应的部分,共享一下。不过,从编程的角度,这些规律已经很明显了)。
3.相同物理操作的指令编码:
这里说的相同物理操作是指CPU运算类型相同的指令,看看下面这组指令:
00401000 8000 12 add byte ptr [eax], 12 80 00[00 0]000 12
00401003 8008 12 or byte ptr [eax], 12 80 00[00 1]000 12
00401006 8010 12 adc byte ptr [eax], 12 80 00[01 0]000 12
00401009 8018 12 sbb byte ptr [eax], 12 80 00[01 1]000 12
0040100C 8020 12 and byte ptr [eax], 12 80 00[10 0]000 12
0040100F 8028 12 sub byte ptr [eax], 12 80 00[10 1]000 12
00401012 8030 12 xor byte ptr [eax], 12 80 00[11 0]000 12
00401015 8038 12 cmp byte ptr [eax], 12 80 00[11 1]000 12
这组指令的本质是相同的,都是CPU对操作码作加法运算。这里的编码用到了上面说起的ModR/M中的3个bit来区分不同的指令。不仅对于操作码为r/m8, imm8类型的操作如此,实际上对于改组指令其他类型的操作编码在Opcode字节中都能找到类似的区分编码,看看下面的指令组:
00 00[00 0]000 add r/m8 r8
01 00[00 0]001 add r/m16/32/64 r16/32/64
02 00[00 0]010 add r8 r/m8
03 00[00 0]011 add r16/32/64 r/m16/32/64
04 00[00 0]100 add al imm8
05 00[00 0]101 add rax imm16/32
08 00[00 1]000 or r/m8 r8
09 00[00 1]001 or r/m16/32/64 r16/32/64
0A 00[00 1]010 or r8 r/m8
0B 00[00 1]011 or r16/32/64 r/m16/32/64
0C 00[00 1]100 or al imm8
0D 00[00 1]101 or rax imm16/32
10 00[01 0]000 adc r/m8 r8
11 00[01 0]001 adc r/m16/32/64 r16/32/64
12 00[01 0]010 adc r8 r/m8
13 00[01 0]011 adc r16/32/64 r/m16/32/64
14 00[01 0]100 adc al imm8
15 00[01 0]101 adc rax imm16/32
18 00[01 1]000 sbb r/m8 r8
19 00[01 1]001 sbb r/m16/32/64 r16/32/64
1A 00[01 1]010 sbb r8 r/m8
1B 00[01 1]011 sbb r16/32/64 r/m16/32/64
1C 00[01 1]100 sbb al imm8
1D 00[01 1]101 sbb rax imm16/32
20 00[10 0]000 and r/m8 r8
21 00[10 0]001 and r/m16/32/64 r16/32/64
22 00[10 0]010 and r8 r/m8
23 00[10 0]011 and r16/32/64 r/m16/32/64
24 00[10 0]100 and al imm8
25 00[10 0]101 and rax imm16/32
28 00[10 1]000 sub r/m8 r8
29 00[10 1]001 sub r/m16/32/64 r16/32/64
2A 00[10 1]010 sub r8 r/m8
2B 00[10 1]011 sub r16/32/64 r/m16/32/64
2C 00[10 1]100 sub al imm8
2D 00[10 1]101 sub rax imm16/32
30 00[11 0]000 xor r/m8 r8
31 00[11 0]001 xor r/m16/32/64 r16/32/64
32 00[11 0]010 xor r8 r/m8
33 00[11 0]011 xor r16/32/64 r/m16/32/64
34 00[11 0]100 xor AL imm8
35 00[11 0]101 xor rAX imm16/32
38 00[11 1]000 cmp r/m8 r8
39 00[11 1]001 cmp r/m16/32/64 r16/32/64
3A 00[11 1]010 cmp r8 r/m8
3B 00[11 1]011 cmp r16/32/64 r/m16/32/64
3C 00[11 1]100 cmp AL imm8
3D 00[11 1]101 cmp rAX imm16/32
这些编码位置intel并没有给出什么特别的名称,然而这些规律是存在的,从编写代码的角度来看这些规律是很有用处的。后面学习完d,w位之后,大家可以看到,上面的这些指令除了名称不同外,其实有着相同的解析方式。相似的编码组还有移位操作指令组(rol ror rcl rcr shl shr sal sar),链式指令组(movs cmps stos lods scas)等等。
4. 段寄存器相关指令的编码
看看下面的指令组:
00401019 06 00[00 0]110 push es
0040101A 07 00[00 0]111 pop es
0040101B 0E 00[00 1]110 push cs
0040101C 90 nop
0040101D 16 00[01 0]110 push ss
0040101E 17 00[01 0]111 pop ss
0040101F 1E 00[01 1]110 push ds
00401020 1F 00[01 1]111 pop ds
386以前,只有这些段寄存器,而pop和push对这些段寄存器的操作,大致还是有些规律的。这个看起来跟上面的操作相似,我之所以单独把这个列出来是因为这些指令“散落”在各个角落,但是他们还是有着一定规律的。把它列出来的另外一个原因就是很多指令操作都是这样,它们的涵义相似,那么总能找到一点两点的小“规律”来简化指令解析的过程。比如下面的这些:
27 001[0 0]111 daa (al)
2F 001[0 1]111 das (al)
37 001[1 0]111 aaa (al, ah)
3F 001[1 1]111 aas (al, ah)
然而,这些都是一些小的,并没有什么真正涵义的“规律”。
上面提到的一些“规律”我想都是对实际的机器码解析过程有所帮助的,至少我认为这些信息或者这些里面的一部分信息最好能编入到指令翻译表中,这样翻译表的才不会有太多的冗余信息。当然,对于用switch..case这样老土的办法实现的反汇编引擎,这些规律是应该而且我认为是必须要考虑的。
现在只是大致介绍了一些intel指令编码的一些“规律”,当然这些规律并不是像d, w, s位(后面介绍)这么通用,但的确存在,这就像ASCII中大小字符转换只需要set或clear字符编码的第5位一样,利用好的确能给人不少方便。
我不知道上面讲的那些是否很混乱,至少我觉得很乱。也不知道这样胡乱地找“规律”是不是有点可笑,因为CPU指令编码是有着固定的编码规则的,指令识别过程最好能像CPU的解码过程一样。能完全模拟电路的过程我想是最完美的,但是,这部分个人理解得十分有限,如果有高手知道设计CPU过程中的指令集的设计过程,还希望能共享一下,大家一起学习。
- 标 题:打造自己的反汇编引擎Intel指令编码学习报告(四)
- 作 者:egogg
- 时 间:2008-10-27 15:12
- 链 接:http://bbs.pediy.com/showthread.php?t=75473