加入看雪很久了,一直只是在汲取营养。
最近正在学习加密与解密,刚好看到组织翻译《The IDA Pro Book》,因此领养第一章。
第一次翻译,请多指教。
第一章 反汇编简介
你可能想知道在一本致力于IDA Pro的书中会介绍些什么。很明显,此书是以IDA为中心,但此书并不打算作为IDA Pro用户手册。取而代之,我们打算把IDA作为讨论逆向工程技术的有利工具(the enabling tool)来用。你将发现这些逆向工程技术在分析多种软件(从漏洞应用程序(vulnerable application)到恶意软件)时很有用。为完成和我们手头任务相关的某些动作,在IDA中要遵循一定的步骤,我们将在合适的时候详细提供。因此,从在最初查看文件时你想执行的基本任务开始,到针对更具挑战的逆向工程问题的IDA高级应用和定制为止,我们将对IDA的能力有个间接的了解。我们不会介绍IDA的所有特性。但你将发现我们介绍的这些特性在应对逆向工程挑战时非常有用,正是这些功能让IDA成为你工具箱中最有效的工具。
在开始介绍IDA的细节之前,介绍一些反汇编过程的基础和回顾其它对编译代码进行逆向工程的有用工具很有用。虽然这些工具中没有一个提供IDA的全部功能,但是它们专注于IDA全部功能的特定部分,并提供了对特定IDA特性的有用领悟(and offer valuable insight into specific IDA features)。这章接下来的部分将讲解反汇编的过程。
反汇编理论
任何一个花过时间学习编程语言的人可能都学习过编程语言的多种阶段。下面将为在学习这些时打瞌睡的人再总结一下。
第一代语言
这些语言是语言的最低级形式,一般由0和1或某些简写形式,如十六进制组成。只有像Skape[1]这样的超人才能读懂它们。由于看起来都差不多,因此很难区分数据和代码,所以在这一级别事情令人很困惑。第一代语言也称为机器语言,在某些情况下叫字节码。机器语言程序通常称为二进制文件。
第二代语言
也叫汇编语言,第二代语言仅仅是一个脱离了机器语言的表查找。通常,第二代语言映射特定的位模式或操作码到短小并容易记忆的字符序列,这种序列叫做助记符。事实上,这些助记符有时候帮助程序员记住了和它们相关的指令。汇编器是程序员用来把他们的汇编语言程序翻译成适合运行的机器语言的工具。
第三代语言
这些语言通过引入关键字和结构与自然语言的表达能力更近了一步。程序员使用结构作为他们的程序的构建块。尽管使用第三代语言编写的程序由于使用了特定操作系统的独特特性而使得程序平台相关了,但是第三代语言通常是平台无关的。FORTRAN,COBOL,C和JAVA是通常引用的例子。程序员通常使用编译器把他们的程序翻译成汇编语言或者一步到位地翻译成机器语言(或者某些大致的等价形式如字节码)。
第四代语言
这些语言虽然存在但是和本书无关,不做讨论。
什么是反汇编
在传统的软件开发模型中,编译器,汇编器和链接器单独或者联合到一起创建可执行程序。为了向后追溯(或者逆向程序),我们使用工具来撤销汇编和编译过程。一点也不奇怪,这些工具叫做反汇编器和反编译器,它们所做的几乎就是它们的名字所暗示的。反汇编器撤销汇编过程,因此我们可以得到汇编语言输出(因此机器语言是输入)。反编译器旨在以汇编或者甚至是机器语言为输入产生高级语言形式的输出。
在充满竞争的软件市场中,“源代码恢复”的许诺总是很诱人,因此在计算机科学中,开发合用的反编译器仍然是一个活跃的研究领域。如下只是反编译比较困难的少数原因。
编译过程是有损的
在机器语言级别没有变量或函数名,变量类型信息只能通过数据怎样被使用而不是明确的类型声明来确定。当你观察到一个32位的数据被传送时,你需要做一些研究工作来确定这32位数据表示的是一个整数,一个32位浮点值还是一个32位指针。
编译是多对多的操作
这意味着源程序可以用多种不同的方式翻译成汇编语言,而机器语言也可以用多种不同的方式翻译回来。因此,编译一个文件并立即将它反编译的结果将和源文件有很大的不同。
反编译器严重依赖语言和库
用设计用来产生C代码的反编译器处理一个Delphi编译器产生的二进制文件将会产生非常奇怪的结果。同样地,用对Windows 编程API毫无所知的反编译器处理Windows二进制文件也不会产生有用的信息。
为了正确地反编译一个二进制文件需要几乎完美的反编译能力
任何反编译阶段的错误或遗漏一定都会影响全部反编译代码。
然而,在反编译前端,慢但是可靠的过程建立了。我将在第23章回顾当今市场上最久经考验的反编译器Hex-Rays。
为什么要反汇编
反汇编工具的目的是在没有源代码时帮助理解程序。通常,需要使用反汇编的情况包括这些:
分析恶意软件
分析闭源软件的脆弱性
分析闭源软件的互操作性
分析编译器产生的代码来验证编译器的性能和正确性
在debug时显示程序指令
接下来的章节将更详细的介绍每一种情况。
恶意软件分析
除非你处理的是基于脚本的蠕虫病毒,恶意软件的作者很少会提供他们的创作的源代码来帮助你。缺乏源代码,你只有非常有限的选择可以用来发现恶意软件到底是怎样运作的。恶意软件分析的两种重要技术是动态分析和静态分析。动态分析就是让恶意软件在一个被小心控制地环境(sandbox)中执行并用系统工具来记录它行为的每一个可观察的方面。相反,静态分析试图简单地通过读程序代码来理解程序的行为,而对恶意软件,程序代码通常由反汇编列表组成。
脆弱性分析(vulnerability analysis)
为简单化,我们把整个安全审计过程分为三步:发现脆弱性(vulnerability),分析脆弱性(vulnerability),exploit开发。不管你是否有源代码,都可以使用相同的步骤,但是,如果你仅仅有二进制文件,需要付出的努力将更多。过程中的第一步是发现程序中潜在的可exploit条件。这通常是通过动态技术如Fuzzing[2]来达成的,但是也可以通过静态分析来完成(通常需要更多的工夫)。一旦发现问题,就需要进一步的分析来确定问题是否可exploit,如果可以,是在什么条件下。
编译器要选择究竟怎样分配程序变量,反汇编列表提供了理解这些需要的细节。例如,程序员声明70个字节的字符数组,当编译器分配空间时,该数组被扩大到80字节,知道这些很有用。编译器究竟是怎样排序全局变量或局部变量的呢?反汇编列表提供了确定这些的唯一方式。在开发exploit时,有必要了解变量的空间关系通常。最终,通过联合使用反汇编器和调试器,就可以开发exploit了。
软件互操作性
当一个软件仅仅以二进制发布时,竞争者要创建可以和它互操作的软件或者为该软件提供插件(plug-in replacement)是非常困难的。一个普遍的例子就是,硬件驱动代码仅仅支持一种平台。当厂商慢于支持或者更糟,拒绝支持在可选的平台上使用他们的硬件时,为了开发支持该硬件的软件驱动,通常可能需要很多的逆向工程努力。在这些情况下,静态代码分析几乎是唯一的方法。通常,为了理解嵌入式固件,分析需要超越软件驱动的范畴。
编译器验证
由于编译器(或汇编器)的目的是产生机器语言,通常需要好的反汇编工具来验证编译器在按照设计规范完成它的工作。除了正确性,分析者对定位优化编译器输出的额外机会感兴趣,立足于安全方面,他们对确定编译器是否使自身妥协而可能在产生的代码中插入后门也感兴趣(ascertaining whether the compiler itself has been compromised to the extent that it may be inserting back doors into generated code)。
调试显示
反汇编器的一个最普遍的应用可能是在调试器中产生代码列表。不幸的是,调试器内嵌的反汇编器相当简单(OllyDbg是一个显著例外)。它们通常不能批量反汇编,在不能确定函数的边界时,它们有时候会回避反汇编。一个好的反汇编器在调试中提供更好的环境语义和上下文,上述是为什么最好联合这样的反汇编器来使用调试器的原因之一。
怎样反汇编
你已经知道反汇编的目的,但反汇编过程到底怎样进行的呢?现在是介绍这些的时候了。考虑一个反汇编器所面对的任务:这有100KB数据,区分代码和数据,把代码转换成显示给用户的汇编语言,并且在该过程中没有遗漏任何信息。这个任务很典型,很困难。在这个任务的结尾,我们可以附加许多特定需求,例如要求反汇编器定位函数,认出跳转表并识别局部变量,这使得反汇编器的工作更加困难。
为了实现我们的所有需求,任何反汇编器都需要在处理我们提供的文件时从大量的算法中进行选取。产生的反汇编列表的质量直接和使用的算法的质量以及算法实现的质量相关。在这一节,我们将讨论当今反汇编机器代码使用的基本算法中的两个。当讲述这些算法的时候,我会指出它们的缺陷。这样你对反汇编器看起来是失败了的情况就有所准备。通过理解反汇编器的局限,你就可以通过手动干预来提升反汇编输出的整体质量。
一个基本反汇编算法
首先,让我们来开发一个简单的算法,该算法以机器语言为输入产生汇编语言输出。在这样做的时候,我们就可以理解自动反汇编过程中的挑战,假设和折中。
第一步
反汇编的第一步是识别出一段被反汇编的代码。这并不像看起来的那么简单。通常,代码和数据混在一起,而区分它们很重要。在最普遍的情况中,一个被反汇编文件符合可执行文件的共同格式如Windows使用的Portable Executable (PE)格式或在许多基于Unix的系统中常见的Executable and linking format(ELF)格式。典型地,这些格式包括定位文件中包含代码的段和代码入口点[3]的机制(通常以十六进制文件头的形式)。
第二步
已经知道一条指令的起始地址,下一步就是读该地址(或文件偏移)包含的值并执行一个表查找来匹配二进制操作码的值和它的汇编语言助记符。依赖于被反汇编的指令集的复杂性,这可能是一个简单的过程,也可能包括几个额外的操作,如弄清楚可能修改指令行为的任何前缀和确定指令需要的操作数。对指令长度可变的指令集,如Intel X86,可能需要取得额外的指令子节来完全地反汇编一条单独指令。
第三步
一旦取得一条指令并译码了需要的操作数,接下来就是格式化它的汇编语言等价形式并作为反汇编列表的一部分输出。可以从不止一种汇编语言输出格式中选择。例如,X86汇编的两种主要的格式是Intel格式和AT&T格式。
X86汇编语法:AT&T VS INTEL
汇编语言源代码有两种主要的语法:AT&T和Intel。尽管它们都是第二代语言,但是它们的语法(从变量,常量和寄存器访问,到段和指令大小覆盖,到间接访问和偏移地址)有很大的不同。AT&T汇编语法用%作为所有寄存器名称的前缀,用$作为文字常量的前缀(也叫做立即数),它的源操作数出现在左边,目的操作数在右边。使用AT&T语法,加4到eax寄存器的指令是:add $0x4,%eax。GNU汇编器(Gas)和的许多其它GNU工具使用AT&T语法,包括gcc和gdb。
Intel语法和AT&T语法的不同在于它不需要寄存器和文字常量前缀,并且操作数的顺序是反过来的,因此源操作数在右边,目的操作数在左边。使用Intel语法的同一加指令是:add eax,0x4。使用Intel语法的汇编器包括Microsoft汇编器(MASM),Borland的Turbo汇编器(TASM),和Netwide 汇编器(NASM)。
第四步
输出一条指令后,我们需要移动到下一条指令并重复前面的过程直到我们反汇编了文件中的所有指令。
有大量确定从那里开始反汇编,怎样选择下一条要反汇编的指令,怎样区分代码和数据,怎样确定什么时候反汇编了最后一条指令的算法。两种最重要的反汇编算法是线性扫描和递归向下。
线性扫描反汇编
线性扫描反汇编算法用一种非常简单而直接的方法来定位要反汇编的指令:一条指令的结束就是另一条指令的开始。因此,最困难的是确定从那里开始。通常的方案是假设程序中标明是代码(典型地,通过程序文件头来指定)的段中包含的都是机器语言指令。反汇编从一个代码段的第一个字节开始,以线性模式扫描区段,一条接一条的反汇编直到到达段结尾。这对通过识别非线性指令,如分支,来弄清楚程序的控制流没有帮助。
在反汇编过程中,要维护一个指向当前正在反汇编的指令的开始的指针。作为反汇编过程的一部分,要计算每一条指令的长度并用来确定下一条要反编译的指令的位置。定长指令的指令集(例如MIPS)更容易反汇编些,因为定位接下来的指令很简单。
线性扫描算法的优点在于它完全覆盖了一个程序的代码段。线性扫描方法的一个主要缺点是它没有注意到代码中可能混有数据的事实。这在表1-1中是很明显的。表1-1是用线性扫描反汇编器反汇编一个函数的输出。这个函数包含一个switch语句,在这个例子中使用的编译器选择使用跳转表来实现switch语句。更进一步说,编译器选择在函数本身中嵌入一个跳转表。401250○1处的jmp语句引用一个从410257○2开始的地址表。不幸的是,反汇编器把410257○2作为一条指令来处理,并错误地产生了对应的汇编语言表示。

表1-1 线性扫描反汇编
如果我们以小结尾[4]方式查看410257○2开始的4字节组,我们看到,每一个都表示一个附近的地址,这个地址实际是多个跳转之一的目的位置(001012e0,0040128b,00401290,…)。因此,○2处的loopne指令并不是一条指令。取而代之,它指出了线性扫描算法在合适地区分代码和数据时的失败。
GNU调试器(gdb),Microsoft的WinDug调试器和objdump工具的反汇编引擎使用的是线性扫描。
递归向下反汇编
递归向下采用不同的方法来定位指令。递归向下集中注意力在控制流的概念上,控制流基于一条指令是否被另一条指令引用来决定是否应该反汇编它。为了理解递归向下反汇编,弄清楚指令怎样影响CPU指令指针很有帮助。
顺序流指令
顺序流指令把执行权传递给紧接着的下一条指令。顺序流指令的例子包括简单算术指令例如add;寄存器到内存传送指令如mov;和栈操作指令如push和pop。对这些指令,反汇编像线性扫描反汇编一样进行。
条件分支指令
条件跳转指令如x86 jnz,提供两种可能的执行路径。如果条件为真,执行分支,必须改变指令指针的值来反映分支的目标。然而,如果条件为假,执行以线性模式继续,可以用线性扫描方法学来反汇编下一条指令。因为不可能在静态环境中确定条件测试的结果,递归向下算法反汇编所有路径。通过添加目标地址到地址列表中,递归向下算法推迟分支目标指令的反汇编。这个地址列表会在稍迟一点被反汇编。
无条件分支指令
无条件分支不遵循线性流模式,因此递归向下算法的处理不同。和顺序流指令一样,执行只能流向唯一一条指令;然而,这条指令不需要紧跟分支指令。事实上,就像在表1-1中所见,根本没有需要在无条件分支后紧跟一条指令。因此,没有理由反汇编紧跟无条件分支的字节。
递归向下反汇编器将试着确定无条件跳转的目标地址并将目标地址添加到要探测的地址列表中。不幸的是,某些无条件跳转指令可能为递归向下反汇编器带来问题。当跳转指令的目标依赖于运行时的值时,不可能用静态分析来确定跳转目标。X86的jmp eax指令证明了这个问题。Eax寄存器只有在程序真正运行时才会包含一个值。由于寄存器在静态分析中没有包含值,我们没有办法确定跳转指令的目标,因此,我们无法确定从哪里继续反汇编过程。
函数调用指令
一旦函数完成,执行通常立即返回到紧跟调用指令的指令,除这个例外以外,函数调用指令以和无条件跳转指令非常相似的方式运转(包括确定指令目标的无能为力,如call eax)。在这点上,它们和条件分支相似,它们都产生两条可执行路径。目标地址被添加到推迟反汇编的列表中,而紧跟调用的指令以和线性扫描相似的方式被反汇编。
从被调用函数返回时,如果程序并不像期望的那样运转时,递归向下就失败了。例如,函数中的代码故意操作函数的返回地址,在函数完成时,将返回到和反汇编器期望的地址不同的位置。接下来的错误列表展示了一个简单的例子,在个例子中,函数foo在返回调用者前简单地加1到返回地址上。

结果,控制并没有真正地传递给紧跟foo调用的○1处的add指令。合适的反汇编如下:

这个列表更清晰地展示了程序的真正流程,在程序中函数foo事实上返回到○2处的mov指令。尽管由于稍微不同的原因,线性扫描反汇编器也不能合适地反汇编这些代码,了解这些很重要。
返回指令
在某些情况下,递归向下算法走到了路径的尽头。函数返回指令(例如x86 ret)没有提供关于下一步将执行什么指令的信息。如果程序确实在执行,可以从运行时栈上取得地址,并在这个地址恢复执行。取而代之,反汇编突然终止了。从这里开始,递归向下反汇编器转向为延迟反汇编而放到一边的地址。反汇编过程从列表中删除一个地址,并从这个地址继续执行。这就是这个反汇编算法得名的递归过程。
递归向下算法的先天优点之一是区分代码和数据的出众能力。作为一个基于控制流的算法,错误地把数据值当做代码反汇编的可能性小得多。递归向下的主要缺点在于跟踪间接代码路径时的无能为力,如使用指针表来查找目的地址的跳转和调用。然而,通过添加某些识别指向代码的指针的启发,递归向下反汇编器可以非常完全地覆盖代码,优秀地识别代码数据。表1-2列出了使用递归向下反汇编器反汇编先前在表1-1中显示的switch语句的输出。
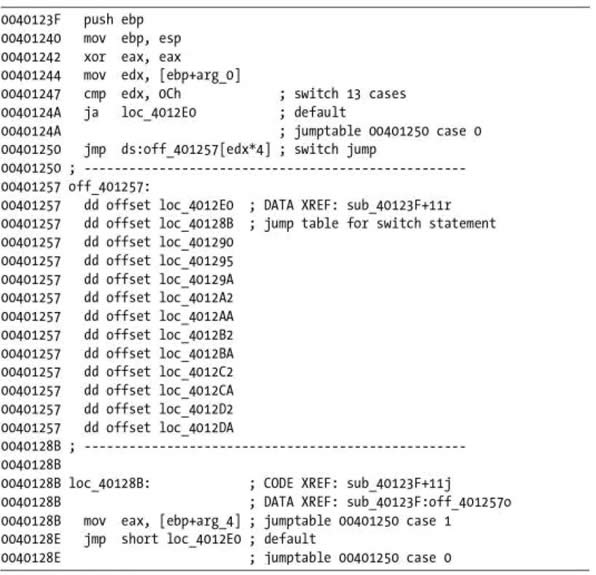
表1-2:递归详细反汇编
注意跳转目标表已经被识别出来并因此做了格式化。IDA Pro是递归向下反汇编器的最显著例子。对递归向下反汇编过程的理解将帮助我们识别出IDA产生不太理想的反汇编的情况,并让我们可以开发策略来提升IDA的输出。
总结
在使用反汇编器时,对反汇编算法的深入理解是必要的吗?是。在逆向工程时,和工具较量是你想花时间来做的最后的事情。IDA许多优点的其中之一是,不像其它许多反汇编器,它给你提供了大量的机会来引导和撤销它的决定。最终的结果是:完美的产出,也就是准确的反汇编,将远远优于其它。(The net result is that the finished product, an accurate disassembly, will be far superior to anything else available)。
在下一章,我们将介绍在许多逆向工程情况下被证明有用的大量现存工具。尽管不直接和IDA相关,但是这些工具中的许多工具都影响了IDA或者被IDA影响,并且,他们帮助解释了在IDA用户界面上可获得的大量信息显示。
【1】 Skape是Metasploit团队的核心成员,他是一名全面的二进制间谍(all-around binary ninja)。
【2】 Fuzzing是一种脆弱性发现技术,依靠为程序产生大量的独特输入,希望这些输入中的某一个可以使程序以可以被探测,被分析和最终exploited的方式失败。
【3】 简单地说,一旦程序被装载到内存中,操作系统把控制传递给一条指令,这条指令的地址就是程序入口点。
【4】 CPU是大结尾还是小结尾依赖于CPU是首先保存多字节值的最高位(大结尾)还是存储多字节值的最低位(小结尾)。
- 标 题:【翻译】The IDA Pro Book(第一章)
- 作 者:catylifen
- 时 间:2008-10-13 13:40:06
- 链 接:http://bbs.pediy.com/showthread.php?t=74564