【文章标题】: OllyHTML脚本详解(三)静态分析API
【文章作者】: dreaman
【作者邮箱】: dreaman_163@163.com
【作者主页】: http://dreaman.haolinju.net
【软件名称】: OllyHTML
【软件大小】: 800KB
【下载地址】: http://dreaman.haolinju.net
【加壳方式】: 无
【保护方式】: 无
【编写语言】: c++
【使用工具】: vc7.1
【操作平台】: win2000以上系统
【软件介绍】: Ollydbg的插件,用以支持用DHTML作脚本
【作者声明】: 个人觉得用DHTML作脚本是能做一些比较复杂的事情的,希望大家能用用:)
我们后面介绍的所有代码片断均可以使用插件菜单OllyHTML=>Scripts链接的脚本列表里的“即时编写与执行脚本”来
试验。
一、插件API总体结构
0.7版的插件帮助里有对每个API比较详细的说明,我们这里主要是从总体上介绍这些API。
1、插件API根对象:window.external.Application
所有其它插件API对象或者作为这个对象的一个属性返回,或者是由某个插件API的方法或属性返回。
在作为资源提供的常量包含文件const.js中已经定义了此对象的一个别名app:
var app=window.external.Application;
根对象主要提供一些全局性的功能,比如允许/禁止调试事件、模拟快捷键操作、LOG、显示某此OD窗口
、获取被调试程序状态、进程ID、进程句柄、线程ID、线程句柄以及全局的线程列表、模块列表、内存
块等。
2、静态分析核心对象Analyser,这个对象在脚本里的访问方法为:app.Analyser
这个对象的主要功能包括汇编、反汇编、DUMP、指令搜索、二进制串搜索、替换、查找线程、内存、模
块、取上/下一条指令地址、取上/下一个过程入口等。
3、断点功能对象BreakPoint(动态调试API),这个对象在脚本里的访问方法为:app.BreakPoint
这个对象的功能包括临时断点、int3断点、条件断点、硬件断点、内存断点的设置与移除等。
4、执行功能对象Execution(动态调试API),这个对象在脚本里的访问方法为:app.Execution
功能主要是控制被调试程序执行的,包括:执行(F9)、执行直到返回、执行直到用户代码、单步跟进(F7)、
单步执行(F8)、异常继续、异常跟进等。
5、跟踪功能对象Tracer(动态调试API),这个对象在脚本里的访问方法为:app.Tracer
功能主要包括设置Hit Trace与Run Trace、监视表达式等。
6、寄存器信息对象Register,由其它API的返回值或作为调试事件处理的参数提供,主要用于获取/设置被调试程
序执行时寄存器的值。
7、调试事件对象DebugEvent,这个对象作为调试事件处理的参数提供,主要用于获取底层OS提供的调试事件相关
的信息。
8、模块对象Module,这个对象由app.Analyser.GetModuleInfo方法返回(app.SelModule/GetModule也返回此对
象),主要提供被调试进程某个模块(exe/dll)的基地址、大小、代码段基地址/大小、数据段基地址、其它段
的基地址等,此外还提供由OD分析出的该模块中的交叉引用(跳转、过程调用等,信息不完全)。
9、汇编结果信息对象AsmInfo,这个对象由app.Analyser.Asm方法返回,提供汇编出的指令的一些信息。
10、反汇编结果信息DisasmInfo,这个是静态分析信息的主要来源,由app.Analyser.Disasm/FindDisasm/FindDisasm2
方法返回,这个对象提供了每一条反汇编出的指令的指令与操作数的各类信息。
11、内存存取对象Memory,这个对象在脚本里的访问方法为:app.Memory
主要功能包括:在指定进程分配/释放内存,设置内存块的访问权限、读写指定进程内存的字符串/UNICODE字符串
/双字/字/字节。
12、表达式计算结果信息对象ResultInfo,这个对象由app.Tracer.CalcExpression方法返回,包括计算表达式的结果
信息。
13、RuntraceInfo对象、这个对象由app.Tracer.GetRegisterInfo方法返回,主要包括Run Trace的寄存器信息。
14、内存信息对象MemoryInfo,这个对象由app.Analyser.GetMemoryInfo方法返回(app.SelMemory/GetMemory也返回
此对象),主要包含被调试进程内存段的相关信息。
15、线程信息对象Thread,这个对象由app.Analyser.GetThreadInfo方法返回(app.SelThread/GetThread也返回此对
象),主要包含被调试进程的线程的相关信息。
16、操作数信息对象OperandInfo,这个对象由DisasmInfo.GetOPInfo方法返回,包括反汇编出的指令的操作数的类型
、使用的寄存器等信息。
17、DumpInfo对象,app.DisasmPane/DumpPane/StackPane属性的返回对象,主要包括CPU窗口的Disasm/Dump/Stack
子窗口的相关信息。
18、IntegerFields, app.IntegerFields属性的返回对象,用于提供反汇编结果搜索的LAMBDA表达式里的整数变量,每
个变量对应到DisasmInfo的一个属性(或t_disasm结构的一个字段),这个对象还提供将这些整数变量通过等于/大于
等于/小于等于操作合成为条件表达式的方法。
19、StringFields, app.StringFields属性的返回对象,用于提供反汇编结果搜索的LAMBDA表达式里的字符串变量,每
个变量对应到DisasmInfo的一个属性(或t_disasm结构的一个字段),这个对象还提供将字符串变量通过Like操作与Match
操作合成为条件表达式的方法。
20、条件对象Condition,用于将多个LAMBDA条件表达式按AND、OR、NOT操作合成为新的条件表达式。
二、如何开始分析?
在分析之前,首先当然是要用OD装入被调试程序,之后运行脚本进行分析,脚本运行时首先需要知道分析的起始地址,
然后它从起始地址逐条指令的进行分析,我们这一节说的就是与获取地址相关的内容。
(一)寻找程序启动代码所在代码段的首地址:
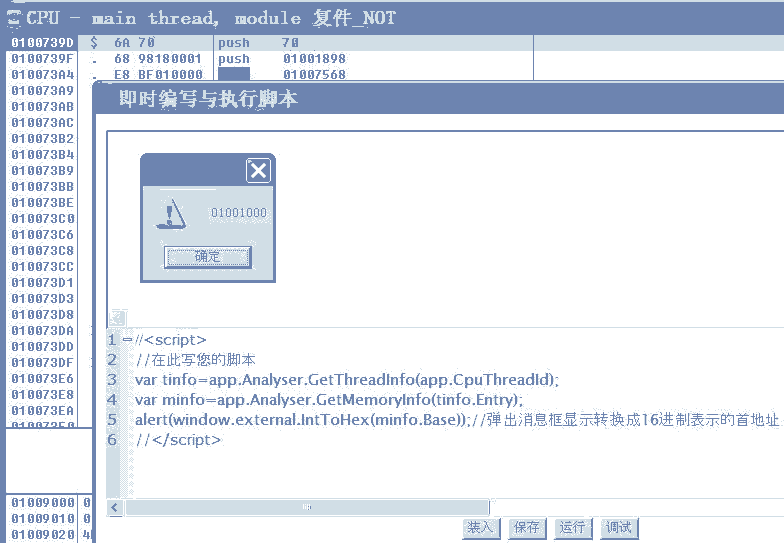
1、利用CPU线程ID得到线程信息:
var tinfo=app.Analyser.GetThreadInfo(app.CpuThreadId);
返回的tinfo是我们在一中介绍的“15、线程信息对象”;
2、根据线程入口地址查找线程入口所在内存段的信息:
var minfo=app.Analyser.GetMemoryInfo(tinfo.Entry);
返回的minfo是我们在一中介绍的“14、内存信息对象”;
3、内存信息对象的Base属性就是线程入口IP所属代码段的首地址:
alert(window.external.IntToHex(minfo.Base));//弹出消息框显示转换成16进制表示的首地址
这个可以作为我们静态分析代码的起始地址。
(二)获取程序主模块的信息:
1、利用CPU线程ID得到线程信息:
var tinfo=app.Analyser.GetThreadInfo(app.CpuThreadId);
返回的tinfo是我们在一中介绍的“15、线程信息对象”;
2、根据线程入口地址查找线程入口所在模块的信息:
var minfo=app.Analyser.GetModuleInfo(tinfo.Entry);
返回的minfo是我们在一中介绍的“8、模块对象”,之后访问此对象的属性与方法即可获取模块的相关信息了:
alert(minfo.Path);//显示模块的路径
(三)取下一条汇编指令的地址:
假设当前指令地址为ip,取下一条指令的语句为:
var newip=app.Analyser.GetNextOPAddr(ip,1);
alert(window.external.IntToHex(newip));//显示新的IP值
有了起始地址以及取下一条指令地址的方法后,我们就可以从起始地址往后逐句分析代码了。这是脚本自动获取起始
地址的情形,如果提供了UI,则首地址还可以由用户输入,特别是对加了壳的程序,脚本自动获取的是壳的代码的起
始地址,而不是原程序代码段的起始地址,或者是对DLL,脚本自动获取的是装入程序的代码段的起始地址(这种情
形可以通过遍历模块列表,找到DLL模块的基地址再分析其内存段获取首地址)。
(四)查找特定模块并获取模块代码段首地址:
1、假设要找的模块名为lpk.dll;
2、获取当前装入的所有模块数:
var mct=app.ModuleNumber;
3、遍历这些模块,搜索指定模块入口值:
var target=0;
for(var i=0;i<mct;i++)
{
var minfo=app.GetModule(i);//得到第i个模块的信息
if(minfo.Path.toLowerCase().indexOf("lpk.dll")>=0)//是否要找的模块
{
target=minfo.Entry;//得到模块入口地址
break;
}
}
4、根据模块入口获取入口所在内存段的首地址:
if(target>0)
{
var mi=app.Analyser.GetMemoryInfo(target);//得到内存段信息
alert(window.external.IntToHex(mi.Base));//显示内存段起始地址
}


三、反汇编
反汇编的API是app.Analyser.Disasm(addr),它返回我们在一中介绍的“10、反汇编结果信息”,我们的分析实际上是对结
果信息的分析,如果我们是在动态调试过程中,反汇编的地址正好是当前EIP,则反汇编结果信息里的是否跳转、操作数
值等信息有效,据此我们可以知道当前程序的运行情况,如果不是在调试状态或者反汇编地址不是当前EIP,则我们只能得
到指令及其操作数的信息,而不能得到操作数引用的实际数据的信息。
通常我们使用反汇编可能主要是在动态调试的过程中分析指令执行的结果,动态调试是我们后面一篇的内容,这里我们主要
介绍一下DisasmInfo对象的比较常用的几个属性(对静态分析,我们可能较少进行逐指令的分析,更多的使用查找,查找的
内容主要在后一小节里):
1、DisasmInfo.IP,这是反汇编指令的地址,在调试时我们还可以从调试事件参数的寄存器信息得到它;
2、DisasmInfo.Disasm,反汇编的结果,如果我们的脚本需要向用户提供信息,通常这个是需要的,它基本上与OD里显示的内
容差不多;
3、DisasmInfo.CmdType,指令的类型,可能的值有(插件的资源常量文件里有这些定义):
C_CMD = 0x00; // 常规指令
C_PSH = 0x10; // PUSH 指令
C_POP = 0x20; // POP 指令
C_MMX = 0x30; // MMX 指令
C_FLT = 0x40; // 浮点指令
C_JMP = 0x50; // 无条件跳转指令
C_JMC = 0x60; // 条件跳转指令
C_CAL = 0x70; // CALL指令
C_RET = 0x80; // RET指令
C_FLG = 0x90; // 改变了FLAGS
C_RTF = 0xA0; // C_JMP 与 C_FLG 同时
C_REP = 0xB0; // 带REPxx 前缀的指令
C_PRI = 0xC0; // 特权指令
C_SSE = 0xD0; // SSE指令
C_NOW = 0xE0; // 3DNow!指令
C_BAD = 0xF0; // 未知指令
一种情形是我们的脚本在模拟手工跟踪操作时,识别指令类型然后采取不同的行动,比如遇到调用指令我们跟进,后向跳转
时我们用F4运行到后一条指令等;
4、DisasmInfo.JumpConst,DisasmInfo.JumpAddr,跳转地址,后者通常需要是当前EIP指令才会有值;
5、DisasmInfo.Condition,是否跳转,仅在当前EIP指令有效,0---未跳转,1---跳转;
6、DisasmInfo.Error,DisasmInfo.Warning,反汇编错误或者指令可疑,有时候它们的值应该很有用;
7、几个用于获取操作数信息的方法,在需要详细分析指令时有用,它们在我们后面介绍的表达式搜索里的用处可能更大一些:
int DisasmInfo.GetOPType (int ix) //取操作数类型,ix (0~2) 索引,DEC_xxx 或 DECR_xxx
int DisasmInfo.GetOPSize (int ix) //取操作数尺寸,ix (0~2) 索引
int DisasmInfo.GetOPGood (int ix) //取对应索引的GetOPAddr/GetOPData是否有效,这些数据仅在当前EIP==IP时生效,ix (0~2) 索引
DWORD DisasmInfo.GetOPAddr (int ix) //操作数内存地址或寄存器索引,这些数据仅在当前EIP==IP时生效,ix (0~2) 索引
DWORD DisasmInfo.GetOPData (int ix) //操作数值(仅整数寄存器值有效),这些数据仅在当前EIP==IP时生效,ix (0~2) 索引
OperandInfo DisasmInfo.GetOPInfo (int ix) //取操作数完整信息,ix (0~2) 索引,返回对象见后面描述
四、搜索(十六进制串搜索与LAMBDA表达式搜索)
(一)十六进制串搜索
这个搜索功能来自OllyScript插件,允许搜索带有通配符的十六进制串,通配符使用'?'代表十六进制串里的一个字符,这样的API有两个,
一个用于一般十六进制串的搜索,一个用于指令十六进制串的搜索:
DWORD app.Analyser.Find (DWORD addr, STRING target)
//从指定地址开始搜索指定内容,这个方法来源于OllyScript
//命令FIND,支持通配符??
//比如
var addr=app.Analyser.Find(0x01001000,"EB??");
alert(window.external.IntToHex(addr));//显示找到十六进制串的地址,若找不到则为0
DWORD app.Analyser.FindOP (DWORD addr, STRING target)
//从指定地址处的指令的下一条指令开始搜索指定指令,这个方法来源于OllyScript
//命令FINDOP,支持通配符??
//比如
var addr=app.Analyser.FindOP(0x01001000,"EB??");
alert(window.external.IntToHex(addr));//显示找到指令的地址,若找不到则为0
(二)指令类型搜索
这个功能从指定地址处的指令的下一条指令开始搜索指定类型的指令:
DisasmInfo app.Anlayser.FindDisasm(DWORD addr,INT cmdType,BOOL onlyConstAddr)
//从指定地址的下一条指令开始搜索指定的指令类型,onlyConstAddr指出是否仅搜索包含
//常量地址的指令,cmdType是前面3中介绍的类型常量,找不到符合条件指令时结果为null
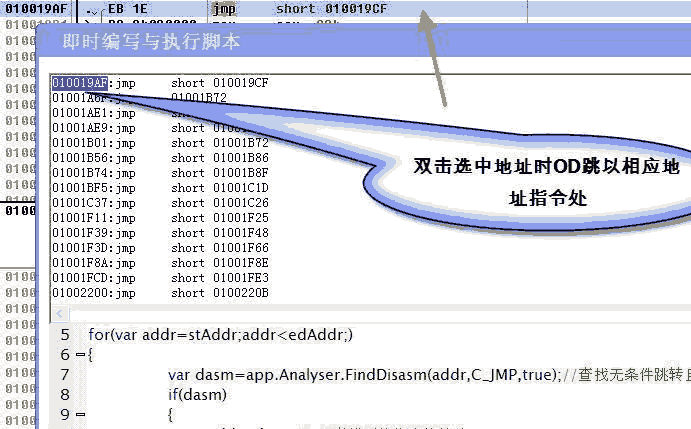
比如我们想要查一下指定地址之间跳转指令,就可以使用这个方法:
//查找01001000~01002000之间的无条件跳转指令(我这里的XP记事本的代码段是01001000开始的)
var stAddr=0x01001000;
var edAddr=0x01002000;
for(var addr=stAddr;addr<edAddr;)
{
var dasm=app.Analyser.FindDisasm(addr,C_JMP,true);//查找无条件跳转且使用常量跳转地址的指令
if(dasm)
{
addr=dasm.IP;//查找到的指令的地址
resultArea.value+=window.external.IntToHex(addr)+":"+dasm.Disasm+"\r\n";//在结果信息控件里显示查找到的指令的地址与指令
//汇编语句,之后双击该地址时会让OD跳转到相应指令(这是“即时编写与执行脚本”这个脚本提供的功能)
addr=app.Analyser.GetNextOPAddr(addr,1);//得到下一条指令地址
}
else
{
break;
}
}
(三)LAMBDA表达式搜索
这是插件提供的对指令搜索的最复杂的搜索功能,所谓LAMBDA表达式,简单说就是带变量的一个表达式,表达式的值不是在书写表达式的时候计算,
而是被延迟到表达式中变量赋于真实值的时候计算,也就是像个函数一样,只有给定自变量的值的时候我们才能求出函数值。
这样,LAMBDA表达式有两个要素:一个是它的变量,另一个是它是表达式,所以有一系列操作。插件支持的LAMBDA表达式由确定的变量集与操作
集构成。
变量集对应到DisasmInfo对象的属性集,我们将它们为分为两类,一类是整数类型的,一类是字符串类型的,分别由app.IntegerFields
对象与app.StringFields对象的属性描述。
因为我们的LAMBDA表达式主要用于搜索,也就是在搜索指令时逐指令的计算LAMBDA表达式的值(我们的LAMBDA表达式的变量集正好对应到DisasmInfo
对象的属性集,也就是对应到每一条指令反汇编出的信息),如果值为真则表明该指令是我们要找的,否则不是,这样,最终用于搜索的表达式
一定是一个条件表达式,所以我们提供的操作都是关于得到一个逻辑值的。操作可分为两类,一类是将我们的变量值通过比较/字符串匹配转化为
逻辑值,另一类是对多个逻辑值的运算,即与、或、非、异或运算。
第一类操作由app.IntegerFields对象与app.StringFields对象的方法实现,这些方法返回代表操作结果Condition对象;
第二类操作由Condition对象的方法实现,它对一个或两个Condition对象实行与/或/非/异或运算,并返回代表运算结果的新的Condition对象。
经过一个或多个变量经过一次第一类操作与多次第二类操作最终得到的Condition对象代表了整个LAMBDA表达式,我们将它传给插件API来实施指令
搜索,这个API是:
DisasmInfo app.Analyser.FindDisasm2(DWORD addr,Condition condition)
//从指定地址的下一条指令开始搜索符合指定LAMBDA表达式的指令,condition是LAMBDA表达式对象
//返回值为搜索到的指令的反汇编信息,如果找不到符合条件的指令,则结果为null
在插件链接的在线脚本列表里有一个“模糊查找反汇编指令”的脚本,这个脚本采用了我们这里提到的三种搜索方法,可以作为我们这一节的一个例子。
接下来我们再看看几个使用LAMBDA表达式搜索的例子:
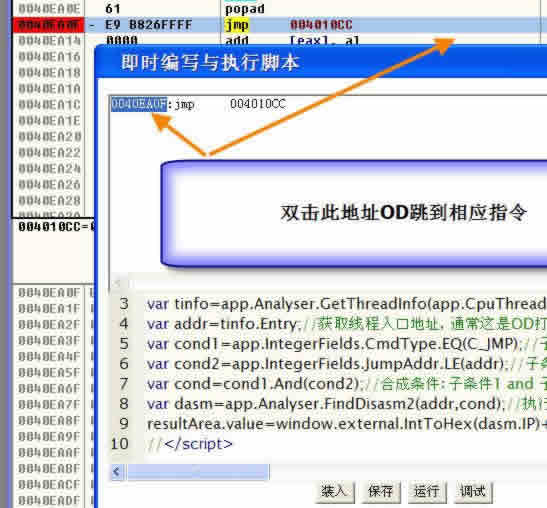
(1)通过寻找向前的跨段跳跃指令寻找UPX加壳程序的入口(试验使用UPX V1.08加壳的一个Win98的记事本)
var tinfo=app.Analyser.GetThreadInfo(app.CpuThreadId);
var addr=tinfo.Entry;//获取线程入口地址,通常这是OD打开程序后停在的那条指令的地址
var cond1=app.IntegerFields.CmdType.EQ(C_JMP);//子条件1:CmdType==C_JMP
var cond2=app.IntegerFields.JumpAddr.LE(addr);//子条件2:JumpAddr<=起始地址
var cond=cond1.And(cond2);//合成条件:子条件1 and 子条件2
var dasm=app.Analyser.FindDisasm2(addr,cond);//执行查找
resultArea.value=window.external.IntToHex(dasm.IP)+":"+dasm.Disasm;//结果显示在结果框,之后双击地址让OD跳到相应指令
执行后我们看到结果框里显示:
0040EA0F:jmp 004010CC
双击0040EA0F,OD会跳到相关指令处:
0040EA06 EB E1 jmp short 0040E9E9
0040EA08 FF96 A8EC0000 call [esi+ECA8]
0040EA0E 61 popad
0040EA0F - E9 B826FFFF jmp 004010CC
0040EA14 0000 add [eax], al
可以看到这是要跳转到98记事本的入口地址004010CC.
(2)字符串模糊匹配,假设我们想要搜索对fs:[0]赋值的语句:
var stAddr=0x01001000;//搜索的起始地址,XP记事本的代码段起始地址
var edAddr=0x01008000;//搜索结束地址
var cond=app.StringFields.Disasm.Like("mov%fs:[0],",true);//搜索条件,搜索串中的‘%’或‘ ’字符用于匹配一个或多个字符,只要指令
//中出现符合搜索串模式的子串条件即为真,第二个参数表示匹配时忽略大小写
for(var addr=stAddr;addr<edAddr;)
{
var dasm=app.Analyser.FindDisasm2(addr,cond);//从addr地址所在指令的下一条指令开始搜索符合条件的指令,找不到返回null
if(dasm)
{
resultArea.value+=window.external.IntToHex(dasm.IP)+":"+dasm.Disasm+"\r\n";//显示找到的指令
addr=dasm.IP;//更新下一次搜索的起始地址
}
else
{
break;
}
}

(3)正则表达式匹配,插件支持符合javascript正则表达式语法规则的正则表达式匹配,使用正则表达式我们可以构造比字符串模糊匹配更精确
的搜索条件(在不使用正则表达式时,字符串模糊匹配可能需要组合(1)中整数变量的条件才能精确匹配一些情形,正则表达式则通常不需要组
合整数变量的条件,当然,也是可以组合的),使用正则表达式作搜索串时,与字符串模糊匹配一样,只要指令中出现符合正则表达式模式的子串
条件即为真,不过正则表达式可以明确的使用'^'来匹配字符串开始,'$'来匹配字符串结束,所以可以写一个正则表达式,它的模式将匹配整个指
令而不仅仅是指令的子串。正则表达式本身是仅次于上下无关语言(就是我们通常的高级语言)表达能力的语言,这里我们仅举个简单的例子看一
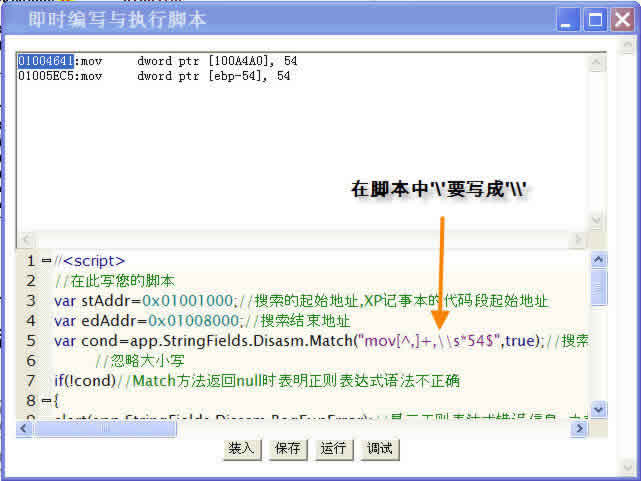
下(在本文最后我们有一段引用的正则表达式语法说明)(当我们在脚本里使用正则表达式串时,因为脚本解释字符串时''字符也是转义符,这与
正则表达式里一样,所以我们对于正则表达式里出现的每一个''字符,在脚本里书写时都要写成'\',如果是由用户接口输入则无需这样,比如
在“模糊查找反汇编指令”脚本的UI界面上输入正则表达式时就不需要将''写成'\'),假设我们想要查找一个mov指令,这个指令的第二个操作数
为立即数54,这个模式的正则表达式如下(在“模糊查找反汇编指令”脚本的UI界面上输入这个表达式就可以搜索这样的指令):
mov[^,]+,\s*54$
脚本如下:
var stAddr=0x01001000;//搜索的起始地址,XP记事本的代码段起始地址
var edAddr=0x01008000;//搜索结束地址
var cond=app.StringFields.Disasm.Match("mov[^,]+,\\s*54$",true);//搜索条件,第一个参数为正则表达式,第二个参数表示匹配时
//忽略大小写
if(!cond)//Match方法返回null时表明正则表达式语法不正确
{
alert(app.StringFields.Disasm.RegExpError);//显示正则表达式错误信息,之前在哪个对象上执行的Match方法就从哪个对象访问
//RegExpError属性
}
else
{
for(var addr=stAddr;addr<edAddr;)
{
var dasm=app.Analyser.FindDisasm2(addr,cond);//从addr地址所在指令的下一条指令开始搜索符合条件的指令,找不到返回null
if(dasm)
{
resultArea.value+=window.external.IntToHex(dasm.IP)+":"+dasm.Disasm+"\r\n";//显示找到的指令
addr=dasm.IP;//更新下一次搜索的起始地址
}
else
{
break;
}
}
}
五、获取或设置OD的界面相关的信息
我们这一部分主要介绍静态分析,脚本作这种分析肯定是为了辅助手动分析,那么我们需要将这些分析的结果显示出来并能够
配合手动进一步分析,典型的情形是,我们用脚本分析一段代码,提取其中具有某些特征的代码,将它们的地址列出来,然后
我们点相应地址可以方便的让OD跳到指定指令,或者,我们可以一次性的在这些指令地址上设置断点。我们现在要介绍的便是
如何让OD显示与处理结果相关的界面。
1、让OD的CPU窗口的各个子窗口显示指定地址:
BOOL app.Analyser.Cpu (DWORD dasmaddr, DWORD dumpaddr, DWORD stackaddr)
//设定CPU窗口的反汇编子窗口、DUMP窗口、栈窗口的地址,某个参数为0表明不改变该子窗口
//的地址
比如我们让OD显示00401000地址的指令与数据,可以写下面语句:
app.Analyser.Cpu(0x00401000,0x00401000,0);
2、在调试中让OD的CPU窗口显示某个线程的上下文信息:
BOOL app.Analyser.CpuWithThread (DWORD tid, DWORD dumpaddr)
//指定CPU窗口与指定线程关联,并改变DUMP窗口地址为指定地址(为0则不改变)
3、在有Run Trace记录的情况下,让OD的CPU窗口显示指定Run Trace记录指令当时的状态:
BOOL app.Analyser.CpuWithRuntrace (DWORD back)
//指定CPU窗口显示Runtrace里的某条指令相关的信息,这个方法主要用于Runtrace跟踪
4、打开一个新DUMP窗口,比如我们想要同时看多个地址的内存数据就可以用这个API:
DWORD app.Analyser.Dump (STRING title, DWORD addr, DWORD len, DWORD type)
//打开一个新的DUMP窗口,参数为(标题,内存起始地址,显示内存块的长度,显示类型),返回值为
//窗口句柄,可用作下一方法的参数从而更新内存地址与长度,显示类型的可能值如下:
0x01101 Hex/ASCII (16 bytes)
0x01081 Hex/ASCII (8 bytes)
0x0A101 Hex/UNICODE (16 bytes)
0x0A081 Hex/UNICODE (8 bytes)
0x02401 ASCII (64 chars)
0x02201 ASCII (32 chars)
0x03402 UNICODE (64 chars)
0x03202 UNICODE (32 chars)
0x04082 Signed short decimal
0x05082 Unsigned short decimal
0x06082 Short hex
0x04044 Signed long decimal
0x05044 Unsigned long decimal
0x06044 Long hex
0x08014 Address
0x0B041 Address with ASCII dump
0x0C041 Address with UNICODE dump
0x07044 32-bit float
0x07028 64-bit double
0x0701A 80-bit long double
0x09011 Disassemble
0x0D001 PE header
假设我们要同时看01001000与01000000的数据,则可以写下面语句:
app.Analyser.Dump("01001000",0x01001000,512,0x01101);
app.Analyser.Dump("01000000",0x01000000,512,0x01101);
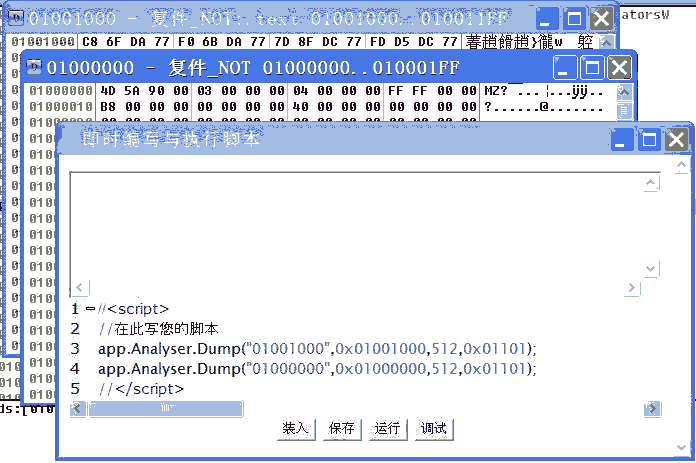
5、更新某个DUMP窗口
BOOL app.Analyser.UpdateDump (DWORD hwnd, DWORD addr, DWORD len, DWORD type)
//更新指定DUMP窗口的内存起始地址与内存块长度,采用指定的显示类型
6、为某条指定添加注释
BOOL app.Analyser.Comment (DWORD addr, STRING cmd)
//为指定地址添加注释
7、选中CPU反汇编窗口的某条或某几条指令
BOOL app.Analyser.SelectDisasm(DWORD addr,DWORD size) //在OD CPU反汇编窗口选中指定地址开始的指定大小的指令
--------------------------------------------------------------------------------
2006年09月22日 17:00:00
附:正则表达式语法说明(PERL,javascript中正则表达式的语法规则)
In regular expressions, all characters match themselves except for the following special characters:
.[{()\*+?|^$
Wildcard:
The single character '.' when used outside of a character set will match any single character except:
Anchors:
A '^' character shall match the start of a line.
A '$' character shall match the end of a line.
Marked sub-expressions:
A section beginning ( and ending ) acts as a marked sub-expression. Whatever matched the sub-expression
is split out in a separate field by the matching algorithms. Marked sub-expressions can also repeated,
or referred to by a back-reference.
Non-marking grouping:
A marked sub-expression is useful to lexically group part of a regular expression, but has the side-effect
of spitting out an extra field in the result. As an alternative you can lexically group part of a regular
expression, without generating a marked sub-expression by using (?: and ) , for example (?:ab)+ will repeat
"ab" without splitting out any separate sub-expressions.
Repeats:
Any atom (a single character, a marked sub-expression, or a character class) can be repeated with the *, +, ?, and {} operators.
The * operator will match the preceding atom zero or more times, for example the expression a*b will match any of the following:
b
ab
aaaaaaaab
The + operator will match the preceding atom one or more times, for example the expression a+b will match any of the following:
ab
aaaaaaaab
But will not match:
b
The ? operator will match the preceding atom zero or one times, for example the expression ca?b will match any of the following:
cb
cab
But will not match:
caab
An atom can also be repeated with a bounded repeat:
a{n} Matches 'a' repeated exactly n times.
a{n,} Matches 'a' repeated n or more times.
a{n, m} Matches 'a' repeated between n and m times inclusive.
For example:
^a{2,3}$
Will match either of:
aa
aaa
But neither of:
a
aaaa
It is an error to use a repeat operator, if the preceding construct can not be repeated, for example:
a(*)
Will raise an error, as there is nothing for the * operator to be applied to.
Non greedy repeats
The normal repeat operators are "greedy", that is to say they will consume as much input as possible. There are non-greedy versions
available that will consume as little input as possible while still producing a match.
*? Matches the previous atom zero or more times, while consuming as little input as possible.
+? Matches the previous atom one or more times, while consuming as little input as possible.
?? Matches the previous atom zero or one times, while consuming as little input as possible.
{n,}? Matches the previous atom n or more times, while consuming as little input as possible.
{n,m}? Matches the previous atom between n and m times, while consuming as little input as possible.
Back references:
An escape character followed by a digit n, where n is in the range 1-9, matches the same string that was matched by sub-expression n.
For example the expression:
^(a*).*\1$
Will match the string:
aaabbaaa
But not the string:
aaabba
Alternation
The | operator will match either of its arguments, so for example: abc|def will match either "abc" or "def".
Parenthesis can be used to group alternations, for example: ab(d|ef) will match either of "abd" or "abef".
Empty alternatives are not allowed (these are almost always a mistake), but if you really want an empty alternative use (?:) as a
placeholder, for example:
"|abc" is not a valid expression, but
"(?:)|abc" is and is equivalent, also the expression:
"(?:abc)??" has exactly the same effect.
Character sets:
A character set is a bracket-expression starting with [ and ending with ], it defines a set of characters, and matches any single
character that is a member of that set.
A bracket expression may contain any combination of the following:
Single characters:
For example [abc], will match any of the characters 'a', 'b', or 'c'.
Character ranges:
For example [a-c] will match any single character in the range 'a' to 'c'.
Negation:
If the bracket-expression begins with the ^ character, then it matches the complement of the characters it contains, for example [^a-c]
matches any character that is not in the range a-c.
Character classes:
An expression of the form [[:name:]] matches the named character class "name", for example [[:lower:]] matches any lower case character.
See character class names.
Collating Elements:
An expression of the form [[.col.] matches the collating element col. A collating element is any single character, or any sequence of
characters that collates as a single unit. Collating elements may also be used as the end point of a range, for example: [[.ae.]-c]
matches the character sequence "ae", plus any single character in the range "ae"-c, assuming that "ae" is treated as a single collating
element in the current locale.
As an extension, a collating element may also be specified via it's symbolic name, for example:
[[.NUL.]]
matches a NUL character.
Equivalence classes:
An expression oftheform[[=col=]], matches any character or collating element whose primary sort key is the same as that for collating
element col, as with colating elements the name col may be a symbolic name. A primary sort key is one that ignores case, accentation,
or locale-specific tailorings; so for example [[=a=]] matches any of the characters: a, à, á, a, ?, ?, ?, A, à, á, ?, ?, ? and ?.
Unfortunately implementation of this is reliant on the platform's collation and localisation support; this feature can not be relied
upon to work portably across all platforms, or even all locales on one platform.
Escapes:
All the escape sequences that match a single character, or a single character class are permitted within a character class definition,
except the negated character classes (\D \W etc).
Combinations:
All of the above can be combined in one character set declaration, for example: [[:digit:]a-c[.NUL.]].
Escapes
Any special character preceded by an escape shall match itself.
The following escape sequences are also supported:
Escapes matching a specific character
The following escape sequences are all synonyms for single characters:
Escape Character
\a '\a'
\e 0x1B
\f \f
\n \n
\r \r
\t \t
\v \v
\b \b (but only inside a character class declaration).
\cX An ASCII escape sequence - the character whose code point is X % 32
\xdd A hexadecimal escape sequence - matches the single character whose code point is 0xdd.
\x{dddd} A hexadecimal escape sequence - matches the single character whose code point is 0xdddd.
\0ddd An octal escape sequence - matches the single character whose code point is 0ddd.
\N{name} Matches the single character which has the symbolic name name. For example \N{newline} matches the single character \n.
"Single character" character classes:
Any escaped character x, if x is the name of a character class shall match any character that is a member of that class, and any
escaped character X, if x is the name of a character class, shall match any character not in that class.
The following are supported by default:
Escape sequence Equivalent to
\d [[:digit:]]
\l [[:lower:]]
\s [[:space:]]
\u [[:upper:]]
\w [[:word:]]
\D [^[:digit:]]
\L [^[:lower:]]
\S [^[:space:]]
\U [^[:upper:]]
\W [^[:word:]]
Character Properties
The character property names in the following table are all equivalent to the names used in character classes.
Form Description Equivalent character set form
\pX Matches any character that has the property X. [[:X:]]
\p{Name} Matches any character that has the property Name. [[:Name:]]
\PX Matches any character that does not have the property X. [^[:X:]]
\P{Name} Matches any character that does not have the property Name. [^[:Name:]]
Word Boundaries
The following escape sequences match the boundaries of words:
\< Matches the start of a word.
\> Matches the end of a word.
\b Matches a word boundary (the start or end of a word).
\B Matches only when not at a word boundary.
Buffer boundaries
The following match only at buffer boundaries: a "buffer" in this context is the whole of the input text that is being
matched against (note that ^ and $ may match embedded newlines within the text).
\` Matches at the start of a buffer only.
' Matches at the end of a buffer only.
\A Matches at the start of a buffer only (the same as \`).
\z Matches at the end of a buffer only (the same as ').
\Z Matches an optional sequence of newlines at the end of a buffer: equivalent to the regular expression \n*\z
Continuation Escape
The sequence \G matches only at the end of the last match found, or at the start of the text being matched if no previous
match was found. This escape useful if you're iterating over the matches contained within a text, and you want each
subsequence match to start where the last one ended.
Quoting escape
The escape sequence \Q begins a "quoted sequence": all the subsequent characters are treated as literals, until either
the end of the regular expression or \E is found. For example the expression: \Q\*+\Ea+ would match either of:
\*+a\*+aaa
Unicode escapes
\C Matches a single code point: in Boost regex this has exactly the same effect as a "." operator.
\X Matches a combining character sequence: that is any non-combining character followed by a sequence of zero or more
combining characters.
Any other escape
Any other escape sequence matches the character that is escaped, for example \@ matches a literal '@'.
Perl Extended Patterns
Perl-specific extensions to the regular expression syntax all start with (?.
Comments
(?# ... ) is treated as a comment, it's contents are ignored.
Modifiers
(?imsx-imsx ... ) alters which of the perl modifiers are in effect within the pattern, changes take effect from the point
that the block is first seen and extend to any enclosing ). Letters before a '-' turn that perl modifier on, letters
afterward, turn it off.
(?imsx-imsx:pattern) applies the specified modifiers to pattern only.
Non-marking grouping
(?:pattern) lexically groups pattern, without generating an additional sub-expression.
Lookahead
(?=pattern) consumes zero characters, only if pattern matches.
(?!pattern) consumes zero characters, only if pattern does not match.
Lookahead is typically used to create the logical AND of two regular expressions, for example if a password must contain a lower
case letter, an upper case letter, a punctuation symbol, and be at least 6 characters long, then the expression:
(?=.*[[:lower:]])(?=.*[[:upper:]])(?=.*[[:punct:]]).{6,}
could be used to validate the password.
Lookbehind
(?<=pattern) consumes zero characters, only if pattern could be matched against the characters preceding the current position
(pattern must be of fixed length).
(?<!pattern) consumes zero characters, only if pattern could not be matched against the characters preceding the current position
(pattern must be of fixed length).
Independent sub-expressions
(?>pattern) pattern is matched independently of the surrounding patterns, the expression will never backtrack into pattern.
Independent sub-expressions are typically used to improve performance; only the best possible match for pattern will be considered,
if this doesn't allow the expression as a whole to match then no match is found at all.
Conditional Expressions
(?(condition)yes-pattern|no-pattern) attempts to match yes-pattern if the condition is true, otherwise attempts to match no-pattern.
(?(condition)yes-pattern) attempts to match yes-pattern if the condition is true, otherwise fails.
Condition may be either a forward lookahead assert, or the index of a marked sub-expression (the condition becomes true if the
sub-expression has been matched).
Operator precedence
The order of precedence for of operators is as shown in the following table:
Collation-related bracket symbols [==] [::] [..]
Escaped characters \
Character set (bracket expression) []
Grouping ()
Single-character-ERE duplication * + ? {m,n}
Concatenation
Anchoring ^$
Alternation |
What gets matched
If you view the regular expression as a directed (possibly cyclic) graph, then the best match found is the first match found by a
depth-first-search performed on that graph, while matching the input text.
Alternatively:
the best match found is the leftmost match, with individual elements matched as follows;
Construct What gets matches
AtomA AtomB Locates the best match for AtomA that has a following match for AtomB.
Expression1 | Expression2 If Expresion1 can be matched then returns that match, otherwise attempts to match Expression2.
S{N} Matches S repeated exactly N times.
S{N,M} Matches S repeated between N and M times, and as many times as possible.
S{N,M}? Matches S repeated between N and M times, and as few times as possible.
S?, S*, S+ The same as S{0,1}, S{0,UINT_MAX}, S{1,UINT_MAX} respectively.
S??, S*?, S+? The same as S{0,1}?, S{0,UINT_MAX}?, S{1,UINT_MAX}? respectively.
(?>S) Matches the best match for S, and only that.
(?=S), (?<=S) Matches only the best match for S (this is only visible if there are capturing parenthesis within S).
(?!S), (?<!S) Considers only whether a match for S exists or not.
(?(condition)yes-pattern | no-pattern) If condition is true, then only yes-pattern is considered, otherwise only no-pattern is considered.